Next: Available window functions and
Up: NFFT - nonequispaced fast
Previous: The case
Contents
In summary, the following Algorithm 1 is obtained for the fast
computation of (2.3) with
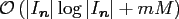 arithmetic operations.
arithmetic operations.
![\begin{algorithm}
% latex2html id marker 440
[ht]
\caption{\tt NFFT
}
Input: $...
...dsymbol{N}}\vert \log \vert\ensuremath{\boldsymbol{N}}\vert+M)$.
\end{algorithm}](img128.png)
Algorithm 1 reads in matrix vector notation as
where
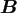 denotes the real
denotes the real
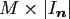 sparse matrix
sparse matrix
where
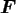 is the Fourier matrix of size
is the Fourier matrix of size
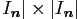 , and where
, and where
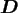 is the real
is the real
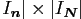 'diagonal' matrix
'diagonal' matrix
with zero matrices
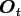 of size
of size
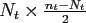 .
.
The corresponding computation of the adjoint matrix vector product reads as
With the help of the transposed index set
one obtains Algorithm 2 for the adjoint NFFT.
![\begin{algorithm}
% latex2html id marker 514
[htbp]
\caption{\tt NFFT$^{{\vdash...
...dsymbol{N}}\vert \log \vert\ensuremath{\boldsymbol{N}}\vert+M)$.
\end{algorithm}](img142.png)
Due to the characterisation of the nonzero elements of the matrix
,
i.e.,
the multiplication with the sparse matrix
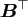 is implemented in a
'transposed' way in the library, summation as outer loop and only using the
multi-index sets
is implemented in a
'transposed' way in the library, summation as outer loop and only using the
multi-index sets
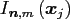 .
.
Next: Available window functions and
Up: NFFT - nonequispaced fast
Previous: The case
Contents
Jens Keiner
2006-11-20