[Previous] [Next]
Servicing an Interrupt
Many devices signal completion of I/O operations by asynchronously interrupting the
processor. In this section, I'll discuss how you configure your driver for interrupt
handling and how you service interrupts when they occur.
Configuring an Interrupt
You configure an interrupt resource in your StartDevice function by calling
IoConnectInterrupt using parameters that you can simply extract from a
CmResourceTypeInterrupt descriptor. Your driver and device need to be entirely ready to work
correctly when you call IoConnectInterrupt—you might even have to service an interrupt
before the function returns—so you normally make the call near the end of the
configuration process. Some devices have a hardware feature that allows you to prevent them
from interrupting. If your device has such a feature, disable interrupts before calling
IoConnectInterrupt and enable them afterward. The extraction and configuration code for an
interrupt would look like this:
1  2
3
4
5
2
3
4
5
|
typedef struct _DEVICE_EXTENSION {
...
PKINTERRUPT InterruptObject;
...} DEVICE_EXTENSION, *PDEVICE_EXTENSION;
ULONG vector; // interrupt vector
KIRQL irql; // interrupt level
KINTERRUPT_MODE mode; // latching mode
KAFFINITY affinity; // processor affinity
BOOLEAN irqshare; // shared interrupt?
...
for (ULONG i = 0; i < nres; ++i, ++resource)
{
switch (resource->Type)
{
case CmResourceTypeInterrupt:
irql = (KIRQL) resource->u.Interrupt.Level;
vector = resource->u.Interrupt.Vector;
affinity = resource->u.Interrupt.Affinity;
mode = (resource->Flags == CM_RESOURCE_INTERRUPT_LATCHED)
? Latched : LevelSensitive;
irqshare = resource->ShareDisposition == CmResourceShareShared;
break;
...
}
...
status = IoConnectInterrupt(&pdx->InterruptObject,
(PKSERVICE_ROUTINE) OnInterrupt, (PVOID) pdx, NULL,
vector, irql, irql, mode, irqshare, affinity, FALSE);
|
- The Level parameter specifies the interrupt request level (IRQL) for this
interrupt.
- The Vector parameter specifies the hardware interrupt vector for this
interrupt. We don't care what this number is, since we're just going to act as a
conduit between the PnP Manager and IoConnectInterrupt. All that matters is that the HAL
understand what the number means.
- Affinity is a bit mask that indicates which CPUs will be allowed to handle this
interrupt.
- We need to tell IoConnectInterrupt whether our interrupt is edge-triggered or
level-triggered. If the resource Flags are CM_RESOURCE_INTERRUPT_LATCHED, we have an edge-triggered interrupt. Otherwise, we have a level-triggered
interrupt.
- Use this statement to discover whether your interrupt is shared.
In the call to IoConnectInterrupt at the end of this sequence, we will simply regurgitate
the values we pulled out of the interrupt resource descriptor. The first argument
(&pdx->InterruptObject) indicates where to store the result of the connection
operation—namely, a pointer to a kernel interrupt object that describes your interrupt.
The second argument (OnInterrupt) is the name of your interrupt service routine;
I'll discuss ISRs a bit further on in this chapter. The third argument (pdx) is a
context value that will be passed as an argument to the ISR each time your device interrupts.
I'll have more to say about this context parameter later as well in "Selecting an Appropriate Context Argument."
The fifth and sixth arguments (vector and irql) specify the interrupt vector
number and interrupt request level, respectively, for the interrupt you're connecting. The
eighth argument (mode) is either Latched or LevelSensitive to indicate
whether the interrupt is edge-triggered or level-triggered. The ninth argument is TRUE if your
interrupt is shared with other devices and FALSE otherwise. The tenth argument
(affinity) is the processor affinity mask for this interrupt. The eleventh and final
argument indicates whether the operating system needs to save the floating-point context when
the device interrupts. Since you're not allowed to do floating-point calculations in an ISR
on an x86 platform, a portable driver would always set this flag to FALSE.
I haven't yet described two other arguments to IoConnectInterrupt. These become important
when your device uses more than one interrupt. In such a case, you would create spin locks for
your interrupts and initialize them by calling KeInitializeSpinLock. You would also
calculate the largest IRQL needed by any of your interrupts before connecting any of them. In
each call to IoConnectInterrupt, you'd specify the address of the appropriate spin lock for
the fourth argument (which is NULL in my example) and you'd specify the maximum IRQL for
the seventh argument (which is irql in my example). This seventh argument indicates the
IRQL used for synchronizing the interrupts, which you should make the maximum of all your
interrupt IRQLs so that you're troubled by only one of your interrupts at a time.
If, however, your device uses only a single interrupt, you won't need a special spin lock
(because the I/O Manager automatically allocates one for you) and the synchronization level for
your interrupt will be the same as the interrupt IRQL.
Handling Interrupts
When your device generates an interrupt, the HAL selects a CPU to service the interrupt
based on the CPU affinity mask you specified. It raises that CPU's IRQL to the appropriate
synchronization level and claims the spin lock associated with your interrupt object. Then it
calls your ISR, which would have the following skeletal form:
BOOLEAN OnInterrupt(PKINTERRUPT InterruptObject, PVOID Context)
{
if (<device not interrupting>)
return FALSE;
<handle interrupt>
return TRUE;
}
|
Windows NT's interrupt-handling mechanism assumes that hardware interrupts can be shared
by many devices. Thus your first job in the ISR is to determine whether your device is
interrupting at the present moment. If not, you return FALSE right away so that the HAL can
send the interrupt to another device driver. If yes, you clear the interrupt at the device
level and return TRUE. Whether the HAL then calls other drivers' ISRs depends on whether
the device interrupt is edge-triggered or level-triggered and on other platform details.
Your main job in the ISR is to service your hardware to clear the interrupt. I'll have
some general things to say about this job, but the details pretty much depend on how your
hardware works. Once you've performed this major task, you return TRUE to indicate to the
HAL that you've serviced a device interrupt.
Programming Restrictions in the ISR
ISRs execute at an IRQL higher than DISPATCH_LEVEL. All code and data used in an ISR must
therefore be in nonpaged memory. Furthermore, the set of kernel-mode functions that an ISR can
call is very limited.
Since an ISR executes at elevated IRQL, it freezes out other activities on its CPU that
require the same or a lower IRQL. For best system performance, therefore, your ISR should
execute as quickly as possible. Basically, do the minimum amount of work required to service
your hardware and return. If there is additional work to do (such as completing an IRP),
schedule a DPC to handle that work.
Despite the admonition you usually receive to do the smallest amount of work possible in
your ISR, you don't want to carry that idea to an extreme. For example, if you're
dealing with a device that interrupts to signal its readiness for the next output byte, go
ahead and send the next byte directly from your ISR. It's fundamentally silly to schedule a
DPC just to transfer a single byte. Remember that the end user wants you to service your
hardware (or else he or she wouldn't have the hardware installed on the computer), and you
are entitled to your fair share of system resources to provide that service.
But don't go crazy calculating pi to a thousand decimal places in your ISR, either (unless
your device requires you to do something that ridiculous, and it probably doesn't). Good
sense should tell you what the right balance of work between an ISR and a DPC routine should
be.
Selecting an Appropriate Context Argument
In the call to IoConnectInterrupt, the third argument is an arbitrary context value that
eventually shows up as the second argument to your ISR. You want to choose this argument so as
to allow your ISR to execute as rapidly as possible; the address of your device object or of
your device extension would be a good choice. The device extension is where you'll be
storing items—such as your device's base port address—that you'll use in
testing whether your device is currently asserting an interrupt. To illustrate, suppose that
your device, which is I/O-mapped, has a status port at its base address and that the low-order
bit of the status value indicates whether the device is currently trying to interrupt. If you
adopt my suggestion, the first few lines of your ISR would read like this:
BOOLEAN OnInterrupt(PKINTERRUPT InterruptObject, PDEVICE_EXTENSION pdx)
{
UCHAR devstatus = READ_PORT_UCHAR(pdx->portbase);
if (!(devstatus & 1))
return FALSE;
<etc.>
}
|
The fully optimized code for this function will require only a few instructions to read the
status port and test the low-order bit.
If you elect to use the device extension as your context argument, be sure to supply a cast
when you call IoConnectInterrupt:
IoConnectInterrupt(..., (PKSERVICE_ROUTINE) OnInterrupt, ...);
|
If you omit the cast, the compiler will generate an exceptionally obscure error mes-sage
because the second argument to your OnInterrupt routine (a PDEVICE_EXTENSION) won't
match the prototype of the function pointer argument to IoConnect-Interrupt, which demands a PVOID.
Synchronizing Operations with the ISR
As a general rule, the ISR shares data and hardware resources with other parts of the
driver. Anytime you hear the word share, you should immediately start thinking about
synchronization problems. For example, a standard UART (universal asynchronous
receiver-transmitter) device has a data port the driver uses for reading and writing data.
You'd expect a serial port driver's ISR to access this port from time to time. Changing
the baud rate also entails setting a control flag called the divisor latch, performing
two single-byte write operations to this same data port, and then clearing the divisor latch.
If the UART were to interrupt in the middle of changing the baud rate, you can see that a data
byte intended to be transmitted could easily end up in the baud-rate divisor register or that a
byte intended for the divisor register could end up being transmitted as data.
The system guards the ISR with a spin lock and with a relatively high IRQL—the device IRQL
(DIRQL). To simplify the mechanics of obtaining the same spin lock and raising IRQL to the same
level as an interrupt, the system provides this service function:
BOOLEAN result = KeSynchronizeExecution(InterruptObject,
SynchRoutine, Context);
|
where InterruptObject (PKINTERRUPT) is a pointer to the interrupt object describing
the interrupt we're trying to synchronize with, SynchRoutine (PKSYNCHRONIZE_ROUTINE) is the address of a callback function in our driver, and Context (PVOID) is an
arbitrary context parameter to be sent to the SynchRoutine as an argument. We use the generic
term synch critical section routine to describe a subroutine that we call by means of
KeSynchronizeExecution. The synch critical section routine has the following
prototype:
BOOLEAN SynchRoutine(PVOID Context);
|
That is, it receives a single argument and returns a BOOLEAN result. When it gets control,
the current CPU is running at the synchronization IRQL that the original call to
IoConnectInterrupt specified, and it owns the spin lock associated with the interrupt.
Consequently, interrupts from the device are temporarily blocked out, and the SynchRoutine can
freely access data and hardware resources that it shares with the ISR.
KeSynchronizeExecution returns whatever value SynchRoutine returns, by the way. This gives
you a way of providing a little bit—actually 8 bits, since BOOLEAN is declared as an
unsigned character—of feedback from SynchRoutine to whatever calls
KeSynchronizeExecution.
Deferred Procedure Calls
Completely servicing a device interrupt often requires you to perform operations that
aren't legal inside an ISR or that are too expensive to carry out at the elevated IRQL of
an ISR. To avoid these problems, the designers of Windows NT provided the deferred procedure
call mechanism. The DPC is a general-purpose mechanism, but you use it most often in connection
with interrupt handling. In the most common scenario, your ISR decides that the current request
is complete and requests a DPC . Later on, the kernel calls your DPC routine at DISPATCH_LEVEL.
While restrictions on what service routines you can call and on paging still apply, fewer
restrictions apply because you're now running at a lower IRQL than inside the ISR. In
particular, it's legal to call routines like IoCompleteRequest or
IoStartNextPacket that are logically necessary at the end of an I/O operation.
Every device object gets a DPC object "for free." That is, the DEVICE_OBJECT has a
DPC object—named, prosaically enough, Dpc—built in. You need to initialize
this built-in DPC object shortly after you create your device object:
NTSTATUS AddDevice(...)
{
PDEVICE_OBJECT fdo;
IoCreateDevice(..., &fdo);
IoInitializeDpcRequest(fdo, DpcForIsr);
...
}
|
IoInitializeDpcRequest is a macro in WDM.H that initializes the device object's
built-in DPC object. The second argument is the address of the DPC procedure that I'll show
you presently.
With your initialized DPC object in place, your ISR can request a DPC by using the following
macro:
BOOLEAN OnInterrupt(...)
{
...
IoRequestDpc(pdx->DeviceObject, NULL, NULL);
...
}
|
This call to IoRequestDpc places your device object's DPC object in a systemwide
queue, as illustrated in Figure 7-5.
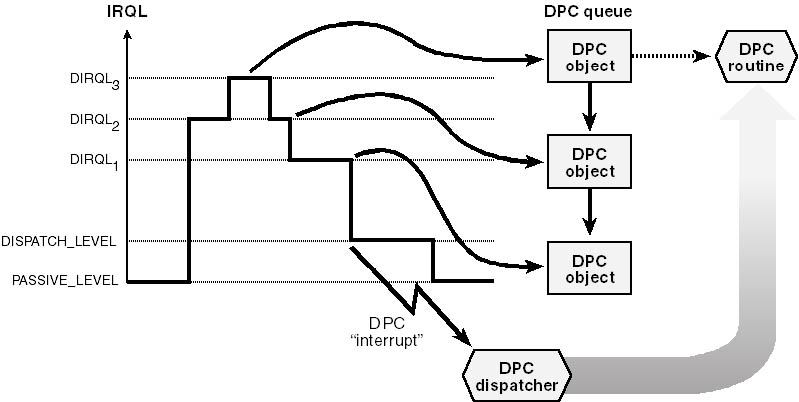
Figure 7-5. Processing DPC requests.
The two NULL parameters are context values that don't really have a good use in this
particular situation. Later on, when no other activity is occurring at DISPATCH_LEVEL,
the kernel removes your DPC object from the queue and calls your DPC routine, which
has the following prototype:
VOID DpcForIsr(PKDPC Dpc, PDEVICE_OBJECT fdo, PIRP junk, PVOID Context)
{
}
|
What you do inside the DPC routine depends in great measure on how your device works. A
likely task would be to complete the current IRP and release the next IRP from the queue. If
you use the "standard model" for IRP queuing, the code would be as follows:
VOID DpcForIsr(...)
{
PIRP Irp = fdo->CurrentIrp;
IoStartNextPacket(fdo, TRUE);
IoCompleteRequest(Irp, <boost value>);
}
|
The TRUE argument to IoStartNextPacket indicates that the next IRP is
cancellable—meaning that the original call to IoStartPacket specified a cancel
routine—and causes IoStartNextPacket to acquire and release the global cancel spin lock
around its access to the device queue and CurrentIrp.
In this code fragment, we rely on the fact that the I/O Manager sets the device object's
CurrentIrp field to point to the IRP it sends to our StartIo routine. The IRP we want to
complete is the one that's the CurrentIrp when we commence the DPC routine. It's
customary to call IoStartNextPacket before IoCompleteRequest so that we can get our
device busy with a new request before we start the potentially long process of completing the
current IRP.
If you use the DEVQUEUE object presented in the previous chapter for IRP queuing, the code
would be similar:
VOID DpcForIsr(...)
{
PDEVICE_EXTENSION pdx = ...;
PIRP Irp = GetCurrentIrp(&pdx->dqRead);
StartNextPacket(&pdx->dqRead, fdo);
IoCompleteRequest(Irp, <boost value>);
}
|
DPC Scheduling
I've glossed over two fairly important details and a minor one about DPCs until now. The
first important detail is implicit in the fact that you have a DPC object that gets put
onto a queue by IoRequestDpc. If your device generates an additional interrupt before the DPC
routine actually runs, and if your ISR requests another DPC, the kernel will simply ignore the
second request. In other words, your DPC object will be on the queue one time no matter how
many DPCs are requested by successive invocations of your ISR, and the kernel will call your
callback routine only one time. During that one invocation, your DPC routine needs to
accomplish all the work related to all the interrupts that have occurred since the last
DPC.
As soon as the DPC dispatcher dequeues your DPC object, it's possible for something to
queue it again, even while your DPC routine executes. This won't cause you any grief if the
object happens to be queued on the same CPU both times. The second important detail about DPC
processing, therefore, has to do with CPU affinity. Normally, the kernel queues a DPC object
for handling on the same processor that requests the DPC—for example, the processor that
just handled an interrupt and called IoRequestDpc. As soon as the DPC dispatcher dequeues the
DPC object and calls your callback routine on one CPU, it's theoretically possible for your
device to interrupt on a different CPU, which might end up requesting a DPC that could
execute simultaneously on that different CPU. Whether simultaneous execution of your DPC
routine poses a problem or not depends, obviously, on the details of your coding.
You can avoid the potential problems that might come from having your DPC routine
simultaneously active on multiple CPUs in several ways. One way, which isn't the best, is
to designate a particular CPU for running your DPC by calling KeSetTargetProcessorDpc.
Also, you could theoretically restrict the CPU affinity of your interrupt when you first
connect it; if you never queue the DPC except from your ISR, you'll never be executing the
DPC on any different CPU. The real reason you're able to specify the CPU affinity of a DPC
or an interrupt, however, is to improve performance by allowing the code and data accessed
during your DPC or ISR routines to remain in a cache.
You can also use a spin lock or other synchronization primitive to prevent interference
between two instances of your DPC routine. Be careful of using a spin lock here: you often need
to coordinate the hypothetical multiple instances of your DPC routine with your ISR, and an ISR
runs at too high an IRQL to use an ordinary spin lock. An interlocked list—that is, one
you manipulate by using support functions in the same family as
ExInterlockedInsertHeadList—might help you, since (so long as you never explicitly
acquire the same spin lock that you use to guard the list) you can use the list at any IRQL.
Interlocked forms of the bitwise OR and AND operators also might help by allowing you to manage
a bit mask (such as a mask indicating recent interrupt conditions) that controls what your DPC
routine is supposed to accomplish; you can cobble these functions together with the help of
InterlockedCompareExchange.
Most simply, you can just make sure that your device won't interrupt in between the time
you request a DPC and the time your DPC routine finishes its work. ("Yo, hardware guys,
stop flooding me with interrupts!")
The third DPC detail, which I consider less crucial than the two I've just explained,
concerns the importance of the DPC. By calling KeSetImportanceDpc, you can
designate one of three importance levels for your DPC:
- MediumImportance is the default and indicates that the DPC should be queued after
all currently queued DPCs. If the DPC is queued to another processor, that other processor
won't necessarily be interrupted right away to service the DPC. If it's queued to the
current processor, the kernel will request a DPC interrupt as soon as possible to begin
servicing DPCs.
- HighImportance causes the DPC to be queued first. If two or more high importance
DPCs get requested at about the same time, the last one queued gets serviced first.
- LowImportance causes the DPC to be queued last. In addition, the kernel won't
necessarily request a DPC interrupt for whatever processor is destined to service the DPC.
The net effect of a DPC's importance level is to influence, but not necessarily control,
how soon the DPC occurs. Even a DPC that has low importance might trigger a DPC interrupt on
another CPU if that other CPU reaches some threshold for queued DPCs or if DPCs haven't
been getting processed fast enough on it. If your device is capable of interrupting again
before your DPC routine runs, changing your DPC to low importance will increase the likelihood
that you'll have multiple work items to perform. If your DPC has an affinity for some CPU
other than the one that requests the DPC, choosing high importance for your DPC will increase
the likelihood that your ISR will still be active when your DPC routine begins to run. But
neither of these possibilities is a certainty; conversely, altering or not altering your
importance can't prevent either of them from happening.
Custom DPC Objects
You can create other DPC objects besides the one named Dpc in a device object. Simply
reserve storage—in your device extension or some other persistent place that isn't
paged—for a KDPC object, and initialize it:
typedef struct _DEVICE_EXTENSION {
...
KDPC CustomDpc;
... };
KeInitializeDpc(&pdx->CustomDpc, (PKDEFERRED_ROUTINE) DpcRoutine, fdo);
|
In the call to KeInitializeDpc, the second argument is the address of a DPC routine
in nonpaged memory, and the third argument is an arbitrary context parameter that will be sent
to the DPC routine as its second argument.
To request a deferred call to a custom DPC routine, call KeInsertQueueDpc:
BOOLEAN inserted = KeInsertQueueDpc(&pdx->CustomDpc, arg1, arg2);
|
Here, arg1 and arg2 are arbitrary context pointers that will be passed to the
custom DPC routine. The return value is FALSE if the DPC object was already in a processor
queue and TRUE otherwise.
Also, you can also remove a DPC object from a processor queue by calling
KeRemoveQueueDpc.
A Simple Interrupt-Driven Device
I wrote the PCI42 sample driver (available on the companion disc) to illustrate how to write
the various different driver routines that a typical interrupt-driven, non-DMA device might
use. The method used to handle such a device is often called programmed I/O (PIO) because
program intervention is required to transfer each unit of data.
PCI42 is a dumbed-down driver for the S5933 PCI chip set from Applied Micro Circuits
Corporation (AMCC). The S5933 acts as a matchmaker between the PCI bus and an add-on device
that implements the actual function of a device. The S5933 is very flexible. In particular, you
can program nonvolatile RAM so as to initialize the PCI configuration space for your device in
any desired way. PCI42 uses the S5933 in its factory default state, however.
To grossly oversimplify matters, a WDM driver communicates with the add-on device connected to
an S5933 either by doing DMA (which I'll discuss in the next major section of this chapter)
or by sending and receiving data through a set of mailbox registers. PCI42 will be using one
byte in one of the mailbox registers to transfer data one byte at a time.
The AMCC development kit for the S5933 (part number S5933DK1) includes two breadboard cards and
an ISA (Industry Standard Architecture) interface card that connects to the S5933 development
board via a ribbon cable. The ISA card allows you to access the S5933 from the add-on device
side in order to provide software simulation of the add-on function. One component of the PCI42
sample is a driver (S5933DK1.SYS) for the ISA card that exports an interface for use by test
programs.
Hardware people will snicker at the simplicity of the way PCI42 manages the device. The
advantage of using such a trivial example is that you'll be able to see each step in the
process of handling an I/O operation unfold at human speed. So chortle right back if your
social dynamics allow it.
Initializing PCI42
The StartDevice function in PCI42 handles a port resource and an interrupt resource.
The port resource describes a collection of sixteen 32-bit operation registers in I/O space,
and the interrupt resource describes the host manifestation of the device's INTA# interrupt
capability. At the end of StartDevice, we have the following device-specific code:
NTSTATUS StartDevice(...)
{
...
ResetDevice(pdx);
status = IoConnectInterrupt(...);
KeSynchronizeExecution(pdx->InterruptObject,
(PKSYNCHRONIZE_ROUTINE) SetupDevice, pdx);
return STATUS_SUCCESS;
}
|
That is, we invoke a helper routine (ResetDevice) to reset the hardware. One of the
tasks for ResetDevice is to prevent the device from generating any interrupts, insofar as
that's possible. Then we call IoConnectInterrupt to connect the device interrupt to
our ISR. Even before IoConnectInterrupt returns, it's possible for our device to generate
an interrupt, so everything about our driver and the hardware has to be ready to go beforehand.
After connecting the interrupt, we invoke another helper routine named SetupDevice to
program the device to act the way we want it to. We must synchronize this step with our ISR
because it uses the same hardware registers as our ISR would use, and we don't want any
possibility of sending the device inconsistent instructions. The SetupDevice call is the last
step in PCI42's StartDevice because—contrary to what I told you in Chapter 2,
"Basic Structure of a WDM Driver"—PCI42 hasn't registered any device
interfaces and therefore has none to enable at this point.
ResetDevice is highly device-specific and reads as follows:
1
2
3
|
VOID ResetDevice(PDEVICE_EXTENSION pdx)
{
PAGED_CODE();
WRITE_PORT_ULONG((PULONG) (pdx->portbase + MCSR), MCSR_RESET);
LARGE_INTEGER timeout;
timeout.QuadPart = -10 * 10000; // i.e., 10 milliseconds
KeDelayExecutionThread(KernelMode, FALSE, &timeout);
WRITE_PORT_ULONG((PULONG) (pdx->portbase + MCSR), 0);
WRITE_PORT_ULONG((PULONG) (pdx->portbase + INTCSR),
INTCSR_INTERRUPT_MASK);
}
|
- The S5933 has a master control/status register (MCSR) that controls bus-mastering
DMA transfers and other actions. Asserting four of these bits resets different features of the
device. I defined the constant MCSR_RESET to be a mask containing all four of these
reset flags. This and other manifest constants for S5933 features are in the S5933.H file
that's part of the PCI42 project.
- Three of the reset flags pertain to features internal to the S5933 and take
effect immediately. Setting the fourth flag to 1 asserts a reset signal for the add-on
function. To deassert the add-on reset, you have to explicitly reset this flag to 0. In
general, you want to give the hardware a little bit of time to recognize a reset pulse.
KeDelayExecutionThread, which I discussed in Chapter 4, "Synchronization," puts
this thread to sleep for about 10 milliseconds. You can raise or lower this constant if your
hardware has different requirements, but don't forget that the timeout will never be less
than the granularity of the system clock. Since we're blocking our thread, we need to be
running at PASSIVE_LEVEL in a nonarbitrary thread context. Those conditions are met because our
ultimate caller is the PnP Manager, which has sent us an IRP_MN_START_DEVICE in the full
expectation that we'd be blocking the system thread we happen to be in.
- The last step in resetting the device is to clear any pending interrupts. The
S5933 has six interrupt flags in an interrupt control/status register (INTCSR). Writing 1 bits
in these six positions clears all pending interrupts. (If we write back a mask value that has a
0 bit in one of the interrupt flag positions, the state of that interrupt is not affected. This
kind of flag bit is called read/write-clear or just R/WC.) Other bits in the INTCSR
enable interrupts of various kinds. By writing 0 bits in those locations, we're disabling
the device to the maximum extent possible.
Our SetupDevice function is quite simple:
VOID SetupDevice(PDEVICE_EXTENSION pdx)
{
WRITE_PORT_ULONG((PULONG) (pdx->portbase + INTCSR),
INTCSR_IMBI_ENABLE
| (INTCSR_MB1 << INTCSR_IMBI_REG_SELECT_SHIFT)
| (INTCSR_BYTE0 << INTCSR_IMBI_BYTE_SELECT_SHIFT)
);
}
|
This function reprograms the INTCSR to specify that we want an interrupt to occur when
there's a change to byte 0 of inbound mailbox register 1. We could have specified other
interrupt conditions for this chip, including the emptying of a particular byte of a specified
outbound mailbox register, the completion of a read DMA transfer, and the completion of a write
DMA transfer.
Starting a Read Operation
PCI42's StartIo routine follows the pattern we've already studied:
1
2
|
VOID StartIo(IN PDEVICE_OBJECT fdo, IN PIRP Irp)
{
PDEVICE_EXTENSION pdx = (PDEVICE_EXTENSION) fdo->DeviceExtension;
PIO_STACK_LOCATION stack = IoGetCurrentIrpStackLocation(Irp);
NTSTATUS status = IoAcquireRemoveLock(&pdx->RemoveLock, Irp);
if (!NT_SUCCESS(status))
{
CompleteRequest(Irp, status, 0);
return;
}
if (!stack->Parameters.Read.Length)
{
StartNextPacket(&pdx->dqReadWrite, fdo);
CompleteRequest(Irp, STATUS_SUCCESS, 0);
return;
}
pdx->buffer = (PUCHAR) Irp->AssociatedIrp.SystemBuffer;
pdx->nbytes = stack->Parameters.Read.Length;
pdx->numxfer = 0;
KeSynchronizeExecution(pdx->InterruptObject,
(PKSYNCHRONIZE_ROUTINE) TransferFirst, pdx);
}
|
- Here, we save parameters in the device extension to describe the ongoing progress
of the input operation we're about to undertake. PCI42 uses the DO_BUFFERED_IO method,
which isn't typical but helps make this driver simple enough to be used as an example.
- Since our interrupt is connected, our device can interrupt at any time. The ISR
will want to transfer data bytes when interrupts happen, but we want to be sure that the ISR is
never confused about which data buffer to use or about the number of bytes we're trying to
read. To restrain our ISR's eagerness, we put a flag in the device extension named
activerequest that's ordinarily FALSE. Now is the time to set that flag to TRUE. As
usual when dealing with a shared resource, we need to synchronize the setting of the flag with
the code in the ISR that tests it, and we therefore need to invoke a SynchCritSection routine
as I previously discussed. It might also happen that a data byte is already available, in which
case the first interrupt will never happen. TransferFirst is a helper routine that
checks for this eventuality and reads the first byte. The add-on function has ways of knowing
that we emptied the mailbox, so it will presumably send the next byte in due course. Here's
TransferFirst:
VOID TransferFirst(PDEVICE_EXTENSION pdx)
{
pdx->activerequest = TRUE;
ULONG mbef = READ_PORT_ULONG((PULONG) (pdx->portbase + MBEF));
if (!(mbef & MBEF_IN1_0))
return;
*pdx->buffer = READ_PORT_UCHAR(pdx->portbase + IMB1);
++pdx->buffer;
++pdx->numxfer;
if (—pdx->nbytes == 0)
{
pdx->activerequest = FALSE;
IoRequestDpc(pdx->DeviceObject, NULL, NULL);
}
}
|
The S5933 has a mailbox empty/full register (MBEF) whose bits indicate the current status of
each byte of each mailbox register. Here, we check whether the register byte we're using
for input (inbound mailbox register 1, byte 0) is presently unread. If so, we read it. That
might exhaust the transfer count. We already have a subroutine (DpcForIsr) that knows
what to do with a complete request, so we request a DPC if this first byte turns out to satisfy
the request. (Recall that we're executing at DIRQL under protection of an interrupt spin
lock because we've been invoked as a SynchCritSection routine, so we can't just
complete the IRP right now.)
Handling the Interrupt
In normal operation with PCI42, the S5933 interrupts when a new data byte arrives in mailbox
1. The following ISR then gains control:
1
2
3
4
5
6
7
8
|
BOOLEAN OnInterrupt(PKINTERRUPT InterruptObject, PDEVICE_EXTENSION pdx)
{
ULONG intcsr = READ_PORT_ULONG((PULONG) (pdx->portbase + INTCSR));
if (!(intcsr & INTCSR_INTERRUPT_PENDING))
return FALSE;
BOOLEAN dpc = FALSE;
PIRP Irp = GetCurrentIrp(&pdx->dqReadWrite);
if (!Irp
|| AreRequestsBeingAborted(&pdx->dqReadWrite)
|| Irp->Cancel)
{
pdx->nbytes = 0;
dpc = Irp != NULL;
}
while (intcsr & INTCSR_INTERRUPT_PENDING)
{
if (intcsr & INTCSR_IMBI)
{
if (pdx->nbytes && pdx->activerequest)
{
*pdx->buffer = READ_PORT_UCHAR(pdx->portbase + IMB1);
++pdx->buffer;
++pdx->numxfer;
if (!—pdx->nbytes)
dpc = TRUE;
}
}
WRITE_PORT_ULONG((PULONG) (pdx->portbase + INTCSR), intcsr);
intcsr = READ_PORT_ULONG((PULONG) (pdx->portbase + INTCSR));
}
if (dpc)
{
pdx->activerequest = FALSE;
IoRequestDpc(pdx->DeviceObject, NULL, NULL);
}
return TRUE;
}
|
- Our first task is to discover whether our own device is trying to interrupt now.
We read the S5933's INTCSR and test a bit (INTCSR_INTERRUPT_PENDING) that summarizes
all pending causes of interrupts. If this bit is clear, we return
immediately. The reason I chose to use the device extension pointer as the context argument to
this routine—back when I called IoConnectInterrupt—should now be clear: we need
immediate access to this structure to get the base port address.
- When we use a DEVQUEUE, we rely on the queue object to keep track of the current
IRP. This interrupt might be one that we don't expect because we're not currently
servicing any IRP. In that case, we still have to clear the interrupt but shouldn't do
anything else.
- It's also possible that a Plug and Play or power event has occurred that will
cause any new IRPs to be rejected by the dispatch routine. The DEVQUEUE's
AreRequestsBeingAborted function tells us that fact so that we can abort the current
request right now. Aborting an active request is a reasonable thing to do with a device such as
this that proceeds byte by byte. Similarly it's a good idea to check whether the IRP has
been cancelled if it will take a long time to finish the IRP. If your device interrupts only
when it's done with a long transfer, you could leave this test out of your ISR.
- We're now embarking on a loop that will terminate when all of our
device's current interrupts have been cleared. At the end of the loop, we'll reread the
INTCSR to determine whether any more interrupt conditions have arisen. If so, we'll repeat
the loop. We're not being greedy with CPU time here—we want to avoid letting
interrupts cascade into the system because servicing an interrupt is by itself relatively
expensive.
- If the S5933 has interrupted because of a mailbox event, we'll read a new
data byte from the mailbox into the I/O buffer for the current IRP. If you were to look in the
MBEF register immediately after the read, you'd see that the bit corresponding to inbound
mailbox register 1, byte 0, gets cleared by the read. Note that we needn't test the MBEF to
determine whether our byte has actually changed because we programmed the device to interrupt
only upon a change to that single byte.
- Writing the INTCSR with its previous contents has the effect of clearing the six
R/WC interrupt bits, not changing a few read-only bits, and preserving the original setting of
all read/write control bits.
- Here, we read the INTCSR to determine whether additional interrupt conditions
have arisen. If so, we'll repeat this loop to service them.
- As we progressed through the preceding code, we set the Boolean dpc
variable to TRUE if a DPC is now appropriate to complete the current IRP.
The DPC routine for PCI42 is as follows:
VOID DpcForIsr(PKDPC Dpc, PDEVICE_OBJECT fdo, PIRP junk, PVOID Context)
{
PDEVICE_EXTENSION pdx = (PDEVICE_EXTENSION) fdo->DeviceExtension;
NTSTATUS status = STATUS_SUCCESS;
PIRP Irp = GetCurrentIrp(&pdx->dqReadWrite);
ULONG info = pdx->numxfer;
StartNextPacket(&pdx->dqReadWrite, fdo);
CompleteRequest(Irp, status, info);
}
|
Testing PCI42
If you want to examine PCI42 in operation, you need to do several things. First obtain and
install an S5933DK1 development board, including the ISA add-in interface card. Use the Add
Hardware wizard to install the S5933DK1.SYS driver and the PCI42.SYS driver. (I found that
Windows 98 initially identified the development board as a nonworking sound card and that I had
to remove it in the Device Manager before I could install PCI42 as its driver. Windows 2000
handled the board normally, but I did encounter an annoying setup freeze when trying to upgrade
from one release candidate to another during the beta phase.)
Then run both the ADDONSIM and TEST programs, which are in the PCI42 directory tree on
the companion disc. ADDONSIM writes a data value to the mailbox via the ISA interface. TEST
reads a data byte from PCI42. Determining the value of the data byte is left as an exercise for
you.
)