In this section, I'll discuss the topic of memory management. Windows 2000 divides the available virtual address space in several ways. One division—a very firm one based on security and integrity concerns—is between user-mode addresses and kernel-mode addresses. Another division, which is almost but not quite coextensive with the first, is between paged and nonpaged memory. All user-mode addresses and some kernel-mode addresses reference page frames that the Memory Manager swaps to and from the disk over time, while some kernel-mode addresses always reference the same page frames in physical memory. Since Windows 2000 allows portions of drivers to be paged, I'll explain how you control the pagability of your driver at the time you build your driver and at run time.
Windows 2000 provides several methods for managing memory. I'll describe two basic service functions—ExAllocatePool and ExFreePool—that you use for allocating and releasing randomly sized blocks from a heap. I'll also describe the primitives that you use for organizing memory blocks into linked lists of structures. Finally, I'll describe the concept of a lookaside list, which allows you to efficiently allocate and release blocks that are all the same size.
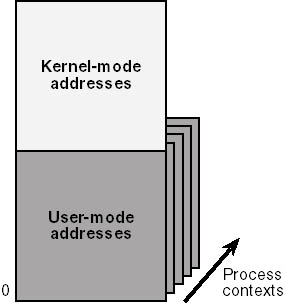
Windows NT and Microsoft Windows 98 run on computers that support a virtual address space, wherein virtual addresses are mapped either to physical memory or (conceptually, anyway) to page frames within a swap file on disk. To grossly simplify matters, you can think of the virtual address space as being divided into two parts: a kernel-mode part and a user-mode part. See Figure 3-7.
Figure 3-7. User-mode and kernel-mode portions of the address space.
Each user-mode process has its own address context, which maps the user-mode virtual addresses to a unique collection of physical page frames. In other words, the meaning of any particular virtual address changes from one moment to the next as the Windows NT scheduler switches from a thread in one process to a thread in another process. Part of the work in switching threads is to change the page tables used by a processor so that they refer to the incoming thread's process context.
NOTE
If you're familiar with the Alpha and you're a stickler for accuracy, you'll know that Alphas don't have page tables. They have something different called translation buffers that map virtual page addresses to physical page addresses. To me, this is a distinction without a difference—on a par with saying that The Odyssey was written by a different Homer than the one historians used to think wrote it. But someone would have sent me an email pointing this out if I didn't say it first.
It's generally unlikely that a WDM driver will execute in the same thread context as the initiator of the I/O requests it handles. We say that we're running "in arbitrary thread context" if we don't know for sure to which process the current user-mode address context belongs. In arbitrary thread context, we simply can't use a virtual address that belongs to user mode because we can't have any idea to what physical memory it might point. In view of this uncertainty, we generally obey the following rule inside a driver program:
Never (well, hardly ever) directly reference user-mode memory.
In other words, don't take an address that a user-mode application provides and treat that address as a pointer that we can directly dereference. I'll discuss in later chapters a few techniques for accessing data buffers that originate in user mode. All we need to know right now, though, is that we're (nearly) always going to be using kernel-mode virtual addresses whenever we want to access the computer's memory.
In a virtual memory system, the operating system organizes physical memory and the swap file into like-sized page frames. In a WDM driver, you can use the manifest constant PAGE_SIZE to tell you how big a page is. In some Windows NT computers, a page is 4096 bytes long; in others, it's 8192 bytes long. There's a related constant named PAGE_SHIFT that equals the page size as a power of two. That is:
PAGE_SIZEĀ==Ā1Ā<<ĀPAGE_SHIFT |
For your convenience, you can use a few preprocessor macros in your code when you're working with the size of a page:
The whole point of a virtual memory system is that you can have a virtual address space that's much bigger than the amount of physical memory on the computer. To accomplish this feat, the Memory Manager needs to swap page frames in and out of physical memory. Certain parts of the operating system can't be paged, though, because they're needed to support the Memory Manager itself. The most obvious example of something that must always be resident in memory is the code that handles page faults (the exceptions that occur when a page frame isn't physically present when needed) and the data structures used by the page fault handler. But the category of "must be resident" stuff is much broader than that.
Windows NT divides the kernel-mode address space into paged and nonpaged memory pools. (The user-mode address space is always pagable.) Things that must always be resident are in the nonpaged pool; things that can come and go on demand are in the paged pool. Windows NT provides a simple rule for deciding whether your code and the data it uses must be resident. I'll elaborate on the rule in the next chapter, but here it is anyway:
Code executing at or above interrupt request level (IRQL) DISPATCH_LEVEL cannot cause page faults.
You can use the PAGED_CODE preprocessor macro (declared in wdm.h) to help you discover violations of this rule in the checked build of your driver. For example:
NTSTATUSĀDispatchPower(PDEVICE_OBJECTĀfdo,ĀPIRPĀIrp)
ĀĀ{
ĀĀPAGED_CODE()
ĀĀ...
ĀĀ}
|
PAGED_CODE contains conditional compilation. In the checked-build environment, it prints a message and generates an assertion failure if the current IRQL is too high. In the free-build environment, it doesn't do anything. If you were to test your driver in a situation where the page containing DispatchPower happened fortuitously to be in memory, you would never discover that it had been called at an elevated IRQL. PAGED_CODE will detect the problem even so. A bug check would occur if the page happened to not be present, so you would certainly learn about the problem then!
Given that some parts of your driver must always be resident and some parts can be paged, you need a way to control the assignment of your code and data to the paged and nonpaged pools. You accomplish part of this job by instructing the compiler how to apportion your code and data among various sections. The run-time loader uses the names of the sections to put parts of your driver in the places you intend. You can also accomplish parts of this job at run time by calling various Memory Manager routines that I'll discuss in the next section.
NOTE
Win32 executable files, including kernel-mode drivers, are internally composed of one or more sections. A section can contain code or data and, generally speaking, has additional attributes such as being readable, writable, sharable, executable, and so on. A section is also the smallest unit that you can designate when you're specifying pagability. When loading a driver image, the system puts sections whose literal names begin with "page" or ".eda" (the start of ".edata") into the paged pool unless the DisablePagingExecutive value in the HKLM\System\CurrentControlSet\Control\Session Manager\Memory Management key happens to be set (in which case no driver paging occurs). In one of the little twists of fate that affect us all from time to time, running Soft-Ice/W on Windows 2000 requires you to disable kernel paging in this way. This certainly makes it harder to find bugs caused by misplacement of driver code or data into the paged pool! If you use this debugger, I recommend that you religiously use the PAGED_CODE macro and the Driver Verifier.
The traditional way of telling the compiler to put code into a particular section is to use the alloc_text pragma. Since not every compiler will necessarily support the pragma, the DDK headers either define or don't define the constant ALLOC_PRAGMA to tell you whether to use the pragma. You can then invoke the pragma to specify the section placement of individual subroutines in your driver, as follows:
#ifdefĀALLOC_PRAGMA ĀĀ#pragmaĀalloc_text(PAGE,ĀAddDevice) ĀĀ#pragmaĀalloc_text(PAGE,ĀDispatchPnp) ĀĀ... #endif |
These statements serve to place the AddDevice and DispatchPnp functions into the pagedĀpool.
The Microsoft C/C++ compiler places two annoying restrictions on using alloc_text:
To control the placement of data variables, you use a different pragma under control of a different preprocessor macro symbol:
#ifdefĀALLOC_DATA_PRAGMA
ĀĀ#pragmaĀdata_seg("PAGE")
#endif
|
The data_seg pragma causes all static data variables declared in a source module after the appearance of the pragma to go into the paged pool. You'll notice that this pragma differs in a fundamental way from alloc_text. A pagable section starts where #pragma data_seg("PAGE") appears and ends where a countervailing #pragma data_seg() appears. Alloc_text, on the other hand, applies to a specific function.
Think twice before putting some of your data into a pagable section, because you might actually be making things worse. The smallest unit that can be paged is PAGE_SIZE long. It's probably silly to put just a few bytes into a pagable section. You'll end up using an entire page worth of memory. Consider, too, that a data page is often "dirty" (that is, changed since it was fetched from disk) and would need to be rewritten to disk before its physical page frame could be reused for another purpose.
Table 3-2 lists the service functions you can use at run time to fine-tune the pagability of your driver in various situations. The purpose of these routines is to let you release the physical memory that would otherwise be tied up by your code and data during periods when it won't be needed. In Chapter 8, for example, I'll discuss how you can register your device with the Power Manager so that you're automatically powered down after a period of inactivity. Powering down might be a good time to release your locked pages.
Table 3-2. Routines for dynamically locking and unlocking driver pages.
| Service Function | Description |
|---|---|
| MmLockPagableCodeSection | Lock a code section given an address inside it |
| MmLockPagableDataSection | Lock a data section given an address inside it |
| MmLockPagableSectionByHandle | Lock a code section by using a handle from a previous MmLockPagableCodeSection call (Windows 2000 only) |
| MmPageEntireDriver | Unlock all pages belonging to driver |
| MmResetDriverPaging | Restore compile-time pagability attributes for entire driver |
| MmUnlockPagableImageSection | Unlock a locked code or data section |
I'm going to describe one way to use these functions to control the pagability of code in your driver. You might want to read the DDK descriptions to learn about other ways to use them. First distribute subroutines in your driver into separately named code sections, like this:
#pragmaĀalloc_text(PAGEIDLE,ĀDispatchRead) #pragmaĀalloc_text(PAGEIDLE,ĀDispatchWrite) ... |
That is, define a section name beginning with "PAGE" and ending in any four-character suffix you please. Then use the alloc_text pragma to place some group of your own routines into that special section. You can have as many special pagable sections as you want, but your logistical problems will grow as you subdivide your driver in this way.
During initialization (say, in DriverEntry), lock your pagable sections like this:
PVOIDĀhPageIdleSection;
NTSTATUSĀDriverEntry(...)
ĀĀ{
ĀĀhPageIdleSectionĀ=ĀMmLockPagableCodeSection((PVOID)ĀDispatchRead);
ĀĀ}
|
When you call MmLockPagableCodeSection, you specify any address at all within the section you're trying to lock. The real purpose of making this call during DriverEntry is to obtain the handle value it returns, which I've shown you saving in a global variable named hPageIdleSection. You'll use that handle much later on, when you decide you don't need a particular section in memory for a while:
MmUnlockPagableImageSection(hPageIdleSection); |
This call will unlock the pages containing the PAGEIDLE section and allow them to move in and out of memory on demand. If you later discover that you need those pages back again, you make this call:
MmLockPagableSectionByHandle(hPageIdleSection); |
Following this call, the PAGEIDLE section will once again be in nonpaged memory (but not necessarily the same physical memory as previously). Note that this function call is available to you only in Windows 2000, and then only if you've included ntddk.h instead of wdm.h. In other situations, you will have to call MmLockPagableCodeSection again.
You can do something similar to place data objects into pagable sections:
PVOIDĀhPageDataSection;
#pragmaĀdata_seg("PAGE")
ULONGĀulSomething;
#pragmaĀdata_seg()
hPageDataSectionĀ=ĀMmLockPagableDataSection((PVOID)Ā&ulSomething);
MmUnlockPagableImageSection(hPageDataSection);
MmLockPagableSectionByHandle(hPageDataSection);
|
I've played fast and loose with my syntax here—these statements would appear in widely disparate parts of your driver.
The key idea behind the Memory Manager service functions I just described is that you initially lock a section containing one or more pages and obtain a handle for use in subsequent calls. You can then unlock the pages in a particular section by calling MmUnlockPagableImageSection and passing the corresponding handle. Relocking the section later on requires a call to MmLockPagableSectionByHandle.
A quick shortcut is available if you're sure that none of your driver will need to be resident for a while. MmPageEntireDriver will mark all the sections in a driver's image as being pagable. Conversely, MmResetDriverPaging will restore the compile-time pagability attributes for the entire driver. To call these routines, you just need the address of some piece of code or data in the driver. For example:
MmPageEntireDriver((PVOID)ĀDriverEntry); ... MmResetDriverPaging((PVOID)ĀDriverEntry); |
You need to exercise care when using any of the Memory Manager routines I've just described if your device uses an interrupt. Spurious interrupts have been known to happen, and it will be very difficult for anyone to discover that the reason for some random crash is that the system tried to call your missing interrupt service routine (ISR) to handle one. The rule stated in the DDK is that you simply mustn't page your ISR or any deferred procedure call (DPC) routine it might schedule after connecting your interrupt.
The basic heap allocation service function in kernel mode used to be ExAllocatePool. This service is still the one referred to in most discussions of heap allocation and used by sample drivers. You call it like this:
PVOIDĀpĀ=ĀExAllocatePool(type,Ānbytes); |
The type argument is one of the POOL_TYPE enumeration constants described in Table 3-3, and nbytes is the number of bytes you want to allocate. The return value is a kernel-mode virtual address pointer to the allocated memory block. Unless you specify either NonPagedPoolMustSucceed or NonPagedPoolCacheAlignedMustS for the pool type, you can receive back a NULL pointer if enough memory isn't available to satisfy your request. If you specify either of those two must-succeed types, lack of memory will cause a bug check with the code MUST_SUCCEED_POOL_EMPTY.
NOTE
Drivers should not allocate memory using one of the "must succeed" specifiers. This is because they can fail whatever operation is underway with a status code if memory is unavailable. Causing a system crash in a low-memory situation is not something a driver should do. Furthermore, only a limited pool of "must succeed" memory exists in the entire system, and the operating system might not be able to allocate memory needed to keep the computer running if drivers tie up some. In fact, Microsoft wishes they had never documented the must-succeed options in the DDK to begin with.
Table 3-3. Pool type arguments for ExAllocatePool.
| Pool Type | Description |
|---|---|
| NonPagedPool | Allocate from the nonpaged pool of memory |
| PagedPool | Allocate from the paged pool of memory |
| NonPagedPoolMustSucceed | Allocate from the nonpaged pool; bugcheck if unable to do so |
| NonPagedPoolCacheAligned | Allocate from the nonpaged pool and ensure that memory is aligned with the CPU cache |
| NonPagedPoolCacheAlignedMustS | Like NonPagedPoolCacheAligned, but bugcheck if unable to allocate |
| PagedPoolCacheAligned | Allocate from the paged pool of memory and ensure that memory is aligned with the CPU cache |
The most basic decision you must make when you call ExAllocatePool is whether the allocated memory block should be swapped out of memory. That choice depends simply on which parts of your driver will need to access the memory block. If you will be using a memory block at or above DISPATCH_LEVEL, you must allocate it from the nonpaged pool. If you'll always use the memory block below DISPATCH_LEVEL, you can allocate from the paged or nonpaged pool as you choose.
The memory block you receive will be aligned to at least an 8-byte boundary. If you place an instance of some structure into the allocated memory, members to which the compiler assigns an offset divisible by 4 or 8 will therefore occupy an address divisible by 4 or 8, too. On some RISC platforms, of course, you must have doubleword and quadword values aligned in this way. For performance reasons, you might want to be sure that the memory block will fit in the fewest possible number of processor cache lines. You can specify one of the XxxCacheAligned type codes to achieve that result. If you ask for at least a page's worth of memory, the block will start on a page boundary.
To release a memory block you previously allocated with ExAllocatePool, you call ExFreePool:
ExFreePool((PVOID)Āp); |
You do need to keep track somehow of the memory you've allocated from the pool in order to release it when it's no longer needed. No one else will do that for you. You must sometimes closely read the DDK documentation of the functions you call with an eye toward memory ownership. For example, in the AddDevice function I showed you in the previous chapter, there's a call to IoRegisterDeviceInterface. That function has a side effect: it allocates a memory block to hold the string that names the interface. You are responsible for releasing that memory later on.
It should go without saying that you need to be extra careful when accessing memory you've allocated from the free storage pools in kernel mode. Since driver code executes in the most privileged mode possible for the processor, there's almost no protection from wild stores.
I said that ExAllocatePool used to be the standard way to allocate memory from a kernel-mode heap. For some time, there has been a variant of ExAllocatePool named ExAllocatePoolWithTag that provides a useful extra feature. For reasons I'll explain presently, you should prefer to use this variant in new drivers even though neither I nor the authors of the DDK samples currently do. This is a clear case of "do as I [actually the people inside Microsoft who make wishes about how programmers use the DDK] say, not as I do."
When you use ExAllocatePoolWithTag, the system allocates 4 more bytes of memory than you asked for and returns you a pointer that's 4 bytes into that block. The tag occupies the initial 4 bytes and therefore precedes the pointer you receive. The tag will be visible to you when you examine memory blocks while debugging or while poring over a crash dump, and it can help you identify the source of a memory block that's involved in some problem or another. For example:
PVOIDĀpĀ=ĀExAllocatePoolWithTag(PagedPool,Ā42,Ā'KNUJ'); |
Here, I used a 32-bit integer constant as the tag value. On a little-endian computer like an x86, the bytes that compose this value will be reversed in memory to spell out a common word in the English language.
Pool tags are also useful as a way of controlling certain features of the Driver Verifier. Please consult the DDK documentation for more information.
It turns out that you're using ExAllocatePoolWithTag even when you think you're calling ExAllocatePool. The declarations of memory allocation functions in wdm.h are under control of a preprocessor macro named POOL_TAGGING. WDM.H (and NTDDK.H too, for that matter) unconditionally defines POOL_TAGGING, with the result that the without-tag functions are actually macro'ed to the equivalent with-tag functions with a tag value of 'mdW' (that is, a space followed by the mirror image of "Wdm"). If POOL_TAGGING were not to be defined in some future release of the DDK, the with-tag functions would be macro'ed to the without-tag versions. Microsoft has no current plans to change the setting of POOL_TAGGING.
Because of the POOL_TAGGING macros, when you write a call to ExAllocatePool in your program, you end up calling ExAllocatePoolWithTag, but the tag you specify is too generic to be of much help. As it turns out, even if you managed to call ExAllocatePool by some subterfuge or another, ExAllocatePool internally calls ExAllocatePoolWithTag with a tag value of 'enoN' (that is, "None"). Since you can't get away from memory tagging, you might as well explicitly call ExAllocatePoolWithTag and specify a usefully unique tag of your own devising. In fact, Microsoft strongly encourages you to do this.
Although ExAllocatePoolWithTag is the function you should use for heap allocation, you would use some variations in special circumstances:
Windows NT makes extensive use of linked lists as a way of organizing collections of similar data structures. In this chapter, I'll discuss the basic service functions you use to manage doubly-linked and singly-linked lists. Separate service functions allow you to share linked lists between threads and across multiple processors; I'll describe those functions in the next chapter after I've explained the synchronization primitives on which they depend.
Whether you organize data structures into a doubly-linked or a singly-linked list, you normally embed a linking substructure—either a LIST_ENTRY or a SINGLE_LIST_ENTRY—into your own data structure. You also reserve a list head element somewhere that uses the same structure as the linking element. For example:
typedefĀstructĀ_TWOWAYĀ
ĀĀ{
ĀĀ...
ĀĀLIST_ENTRYĀlinkfield;
ĀĀ...
ĀĀ}ĀTWOWAY,Ā*PTWOWAY;
LIST_ENTRYĀDoubleHead;
typedefĀstructĀ_ONEWAY
ĀĀ{
ĀĀ...
ĀĀSINGLE_LIST_ENTRYĀlinkfield;
ĀĀ...
ĀĀ}ĀONEWAY,Ā*PONEWAY;
SINGLE_LIST_ENTRYĀSingleHead;
|
When you call one of the list-management service functions, you always work with the linking field or the list head—never directly with the containing structures themselves. So, suppose you've got a pointer (pdElement) to one of your TWOWAY structures. To put that structure onto a list, you'd reference the embedded linking field like this:
InsertTailList(&DoubleHead,Ā&pdElement->linkfield); |
Similarly, when you retrieve an element from a list, you're really getting the address of the embedded linking field. To recover the address of the containing structure, you can use the CONTAINING_RECORD macro. (See Figure 3-8.)
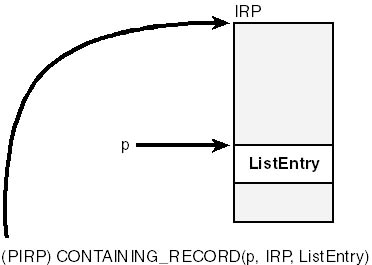
Figure 3-8. The CONTAINING_RECORD macro.
So, if you wanted to process and discard all the elements in a singly-linked list, your code would look something like this:
PSINGLE_LIST_ENTRYĀpsLinkĀ=ĀPopEntryList(&SingleHead);
whileĀ(psLink)
ĀĀ{
ĀĀPONEWAYĀpsElementĀ=Ā(PONEWAY)ĀCONTAINING_RECORD(psLink,
ĀĀĀĀONEWAY,Ālinkfield);
ĀĀ...
ĀĀExFreePool(psElement);
ĀĀpsLinkĀ=ĀPopEntryList(&SingleHead);
ĀĀ}
|
Just before the start of this loop, and again after every iteration, you retrieve the current first element of the list by calling PopEntryList. PopEntryList returns the address of the linking field within a ONEWAY structure, or else it returns NULL to signify that the list is empty. Don't just indiscriminately use CONTAINING_RECORD to develop an element address that you then test for NULL—you need to test the link field address that PopEntryList returns!
A doubly-linked list links its elements both backward and forward in a circular fashion. See Figure 3-9. That is, starting with any element, you can proceed forward or backward in a circle and get back to the same element. The key feature of a doubly-linked list is that you can add or remove elements anywhere in the list.
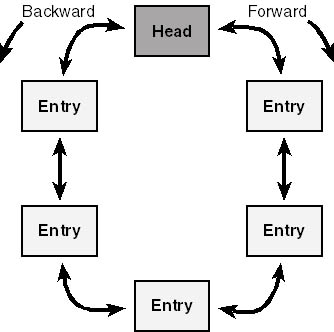
Figure 3-9. Topology of a doubly-linked list.
Table 3-4 lists the service functions you use to manage a doubly-linked list.
Table 3-4. Service functions for use with doubly-linked lists.
| Service Function or Macro | Description |
|---|---|
| InitializeListHead | Initialize the LIST_ENTRY at the head of the list |
| InsertHeadList | Insert element at the beginning |
| InsertTailList | Insert element at the end |
| IsListEmpty | Is list empty? |
| RemoveEntryList | Remove element |
| RemoveHeadList | Remove first element |
| RemoveTailList | Remove last element |
Here is a fragment of a fictitious program to illustrate how to use some of these functions:
1 |
ĀĀtypedefĀstructĀ_TWOWAYĀ{
ĀĀĀĀ...
ĀĀĀĀLIST_ENTRYĀlinkfield;
ĀĀĀĀ...
ĀĀĀĀ}ĀTWOWAY,Ā*PTWOWAY;
ĀĀLIST_ENTRYĀDoubleHead;
ĀĀInitializeListHead(&DoubleHead);
ĀĀASSERT(IsListEmpty(&DoubleHead));
ĀĀPTWOWAYĀpdElementĀ=Ā(PTWOWAY)ĀExAllocatePool(PagedPool,
ĀĀĀĀsizeof(TWOWAY));
ĀĀInsertTailList(&DoubleHead,Ā&pdElement->linkfield);
ĀĀ...
ĀĀifĀ(!IsListEmpty(&DoubleHead))
ĀĀĀĀ{
ĀĀĀĀPLIST_ENTRYĀpdLinkĀ=ĀRemoveHeadList(&DoubleHead);
ĀĀĀĀpdElementĀ=ĀCONTAINING_RECORD(pdLink,ĀTWOWAY,Ālinkfield);
ĀĀĀĀ...
ĀĀĀĀExFreePool(pdElement);
ĀĀĀĀ}
|
It's important to know the exact way RemoveHeadList and RemoveTailList are implemented if you want to avoid errors. For example, consider the following innocent looking statement.
ifĀ(<some-expr>) ĀĀpdLinkĀ=ĀRemoveHeadList(&DoubleHead); |
What I obviously intended with this construction was to conditionally extract the first element from a list. C'est raisonnable, n'est-ce pas? But no, when you debug this later on, you find that elements keep mysteriously disappearing from the list. You discover that pdLink gets updated only when the if expression is TRUE but that RemoveHeadList seems to get called even when the expression is FALSE.
Mon dieu! What's going on here? Well, RemoveHeadList is really a macro that expands into multiple statements. Here's what the compiler really sees in the above statement:
ifĀ(<some-expr>)
ĀĀpdLinkĀ=Ā(&DoubleHead)->Flink;
{{
PLIST_ENTRYĀ_EX_Blink;
PLIST_ENTRYĀ_EX_Flink;
_EX_FlinkĀ=Ā((&DoubleHead)->Flink)->Flink;
_EX_BlinkĀ=Ā((&DoubleHead)->Flink)->Blink;
_EX_Blink->FlinkĀ=Ā_EX_Flink;
_EX_Flink->BlinkĀ=Ā_EX_Blink;
}}
|
Aha! Now the reason for the mysterious disappearance of list elements becomes clear. The TRUE branch of the if statement consists of just the single statement pdLink = (&DoubleHead)->Flink that stores a pointer to the first element. The logic that removes a list element stands alone outside the scope of the if statement and is therefore always executed. Both RemoveHeadList and RemoveTailList amount to an expression plus a compound statement, and you dare not use either of them in a spot where the syntax requires an expression or statement alone. Zut alors!
The other list-manipulation macros don't have this problem, by the way. The difficulty with RemoveHeadList and RemoveTailList arises because they have to return a value and do some list manipulation. The other macros do only one or the other, and they're syntactically safe when used as intended.
A singly-linked list links its elements in only one direction, as illustrated in Figure 3-10. Windows NT uses singly-linked lists to implement pushdown stacks, as suggested by the names of the service routines in Table 3-5. Just as was true for doubly-linked lists, these "functions" are actually implemented as macros in wdm.h, and similar cautions apply. PushEntryList and PopEntryList generate multiple statements, so you can use them only on the right side of an equal sign in a context where the compiler is expecting multiple statements.
Table 3-5. Service functions for use with singly-linked lists.
| Service Function or Macro | Description |
|---|---|
| PushEntryList | Add element to top of list |
| PopEntryList | Remove topmost element |
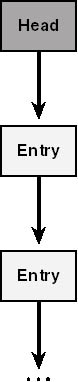
Figure 3-10. Topology of a singly-linked list.
The following pseudofunction illustrates how to manipulate a singly-linked list:
1 |
ĀĀtypedefĀstructĀ_ONEWAYĀ{
ĀĀ...
ĀĀSINGLE_LIST_ENTRYĀlinkfield;
ĀĀ}ĀONEWAY,Ā*PONEWAY;
ĀĀSINGLE_LIST_ENTRYĀSingleHead;
ĀĀSingleHead.NextĀ=ĀNULL;
ĀĀPONEWAYĀpsElementĀ=Ā(PONEWAY)ĀExAllocatePool(PagedPool,
ĀĀĀĀsizeof(ONEWAY));
ĀĀPushEntryList(&SingleHead,Ā&psElement->linkfield);
ĀĀSINGLE_LIST_ENTRYĀpsLinkĀ=ĀPopEntryList(&SingleHead);
ĀĀifĀ(psLink)
ĀĀĀĀ{
ĀĀĀĀpsElementĀ=ĀCONTAINING_RECORD(psLink,ĀONEWAY,Ālinkfield);
ĀĀĀĀ...
ĀĀĀĀExFreePool(psElement);
ĀĀĀĀ}
|
Even employing the best possible algorithms, a heap manager that deals with randomly sized blocks of memory will require some scarce processor time to coalesce adjacent free blocks from time to time. Figure 3-11 illustrates how, when something returns block B to the heap at a time when blocks A and C are already free, the heap manager can combine blocks A, B, and C to form a single large block. The large block is then available to satisfy some later request for a block bigger than any of the original three components.
)
Figure 3-11. Coalescing adjacent free blocks in a heap.
If you know you're always going to be working with fixed-size blocks of memory, you can craft a much more efficient scheme for managing a heap. You could, for example, preallocate a large block of memory that you subdivide into pieces of the given fixed size. Then you could devise some scheme for knowing which blocks are free and which are in use, as suggested by Figure 3-12. Returning a block to such a heap merely involves marking it as free—you don't need to coalesce it with adjacent blocks because you never need to satisfy randomly sized requests.
Merely allocating a large block that you subdivide might not be the best way to implement a fixed-size heap, though. In general, it's hard to guess how much memory to preallocate. If you guess too high, you'll be wasting memory. If you guess too low, your algorithm will either fail when it runs out (bad!) or make too frequent trips to a surrounding random heap manager to get space for more blocks (better). Microsoft has created the lookaside list object and a set of adaptive algorithms to deal with these shortcomings.
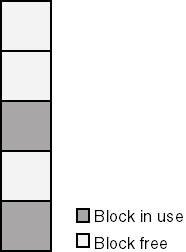
Figure 3-12. A heap containing fixed-size blocks.
Figure 3-13 illustrates the concept of a lookaside list. Imagine that you had a glass that you could (somehow—the laws of physics don't exactly make this easy!) balance upright in a swimming pool. The glass represents the lookaside list object. When you initialize the object, you tell the system how big the memory blocks (water drops, in this analogy) are that you'll be working with. In earlier versions of Windows NT, you could also specify the capacity of the glass, but the operating system now determines that adaptively. To allocate a memory block, the system first tries to remove one from the list (remove a water drop from the glass). If there are no more, the system dips into the surrounding memory pool. Conversely, to return a memory block, the system first tries to put it back onto the list (add a water drop to the glass). But if the list is full, the block goes back into the pool using the regular heap manager routine (the drop slops over into the swimming pool).
)
Figure 3-13. Lookaside lists.
The system periodically adjusts the depths of all lookaside lists based on actual usage. The details of the algorithm aren't really important, and they're subject to change in any case. Basically (in the current release, anyway), the system will reduce the depth of lookaside lists that haven't been accessed recently or that aren't forcing pool access at least 5 percent of the time. The depth never goes below 4, however, which is also the initial depth of a new list.
Table 3-6 lists the eight service functions that you use when you work with a lookaside list. There are really two sets of four functions, one set for a lookaside list that manages paged memory (the ExXxxPagedLookasideList set) and another for a lookaside list that manages nonpaged memory (the ExXxxNPagedLookasideList set). The first thing you must do is reserve nonpaged memory for a PAGED_LOOKASIDE_LIST or an NPAGED_LOOKASIDE_LIST object. These objects are similar. The paged variety uses a FAST_MUTEX for synchronization, whereas the nonpaged variety uses a spin lock. (See the next chapter for a discussion of both of these synchronization objects.) Even the paged variety of object needs to be in nonpaged memory because the system might access it at an elevated IRQL.
Table 3-6. Service functions for lookaside lists.
| Service Function | Description |
|---|---|
| ExInitializeNPagedLookasideList ExInitializePagedLookasideList |
Initialize a lookaside list |
| ExAllocateFromNPagedLookasideList ExAllocateFromPagedLookasideList |
Allocate a fixed-size block |
| ExFreeToNPagedLookasideList ExFreeToPagedLookasideList |
Release a block back to a lookaside list |
| ExDeleteNPagedLookasideList ExDeletePagedLookasideList |
Destroy a lookaside list |
After reserving storage for the lookaside list object somewhere, you call the appropriate initialization routine:
PPAGED_LOOKASIDE_LISTĀpagedlist; PNPAGED_LOOKASIDE_LISTĀnonpagedlist; ExInitializePagedLookasideList(pagedlist,ĀAllocate,ĀFree, ĀĀ0,Āblocksize,Ātag,Ā0); ExInitializeNPagedLookasideList(nonpagedlist,ĀAllocate,ĀFree, ĀĀ0,Āblocksize,Ātag,Ā0); |
(The only difference between the two examples is the spelling of the function name and the first argument.)
The first argument to either of these functions points to the [N]PAGED_LOOKASIDE_LIST object for which you've already reserved space. Allocate and Free are pointers to routines you can write to allocate or release memory from a random heap. You can use NULL for either or both of these parameters, in which case ExAllocatePoolWithTag and ExFreePool will be used, respectively. The blocksize parameter is the size of the memory blocks you will be allocating from the list, and tag is the 32-bit tag value you want placed in front of each such block. (Look back to the section entitled "Variations on ExAllocatePool" for an explanation of the tagging concept.) The two zero arguments are placeholders for values that you supplied in previous versions of Windows NT but which the system now determines on its own; these values are flags to control the type of allocation and the depth of the lookaside list.
To allocate a memory block from the list, call the appropriate AllocateFrom function:
PVOIDĀpĀ=ĀExAllocateFromPagedLookasideList(pagedlist); PVOIDĀqĀ=ĀExAllocateFromNPagedLookasideList(nonpagedlist); |
To put a block back onto the list, call the appropriate FreeTo function:
ExFreeToPagedLookasideList(pagedlist,Āp); ExFreeToNPagedLookasideList(nonpagedlist,Āq); |
Finally, to destroy a list, call the appropriate Delete function:
ExDeletePagedLookasidelist(pagedlist); ExDeleteNPagedLookasideList(nonpagedlist); |
It's a common mistake to forget to delete a lookaside list. You won't be making such a mistake of course, but you might need to advise one of your coworkers about how to avoid it(!). You can tell him or her, "Be sure to do that before your lookaside list passes out of scope. If you created a lookaside list during AddDevice, for example, you probably put the object into your device object and want to delete the list before you call IoDeleteDevice. If you created a lookaside list during DriverEntry, you probably put the object into a global variable and want to delete the list before you return from your DriverUnload routine."