1 Einführung: Was ist linear an linearen Modellen?
In der Diskussion um lineare Modelle gibt es zwei wichtige Konzepte, die oft durcheinandergeraten:
- lineare Funktion und
- lineare Kombination / lineares Modell in den Parametern
Ein hervorragender Blogbeitrag findet sich auch hier:
Titz (2023) – Lineare und nichtlineare Modelle
Wenn in der Statistik von einem „linearen Modell“ die Rede ist, meint man fast immer: Das Modell ist linear in den Parametern, aber der Zusammenhang der erklärenden Variablen selbst muss nicht linear sein.
Ich möchte diesen Unterschied an einem berühmten Beispiel erklären – der Vergessenskurve von Ebbinghaus (1885) und dabei konkret auf Kapitel 7 seines berühmten Werkes „Über das Gedächtnis“ eingehen.
Ich werde zeigen, warum es sich nicht um ein lineares Modell handelt und wie die Vergessenskurve in ein lineares Modell transformiert werden kann.
2. Lineare Funktion / linearer Zusammenhang
Im Schulkontext ist „linear“ meist gleichbedeutend mit „Gerade“. Eine lineare Funktion einer einzigen Variablen x hat dort die Form
\[ Y = a + b x \]
Graphisch ist das eine Gerade: Ändert sich x um 1 Einheit, ändert sich Y immer um b Einheiten, unabhängig davon, an welcher Stelle auf der x-Achse wir uns befinden.
Sobald Terme wie \(x^2\) oder \(\log(x)\) vorkommen, ist der Zusammenhang zwischen x und Y im üblichen geometrischen Sinn nicht mehr linear (keine Gerade mehr).
Beispiel:
\[ Y = a + b_1 x + b_2 x^2 \]
Aber: Die aus den Daten geschätzten Parameter \(b_1\) und \(b_2\) bilden eine lineare Kombination für den Erwartungswert von \(Y\)
\[ E(Y \mid x) = a + b_1 x + b_2x^2 \]
3. Eine nicht lineare Kombination von Parametern
Ebbinghaus entwickelte folgende Gleichung für das Behalten \(b\) bzw. Vergessen \(v\) in Abhängigkeit der Zeit \(t\).
\[ b(t) = \frac{100 \, k}{(\log t)^c + k} \]
Das prozentuale Vergessen ist dann definiert mit
\[ v(t) = 100 - b(t). \]
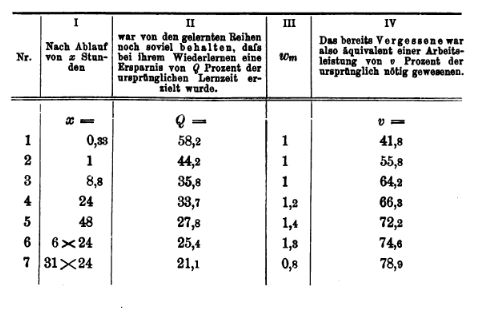
Dafür lernte er sinnlose dreizehnsilbige Reihen auswendig und ermittelte die dafür benötigte Zeit \(L\). Anschließend lernte er dieselben Reihen nach sieben festen Zeitintervallen erneut
- 0,33 Stunden
- 1 Stunde
- 8,8 Stunden
- 24 Stunden
- 2 x 24 Stunden
- 6 x 24 Stunden
- 31 x 24 Stunden
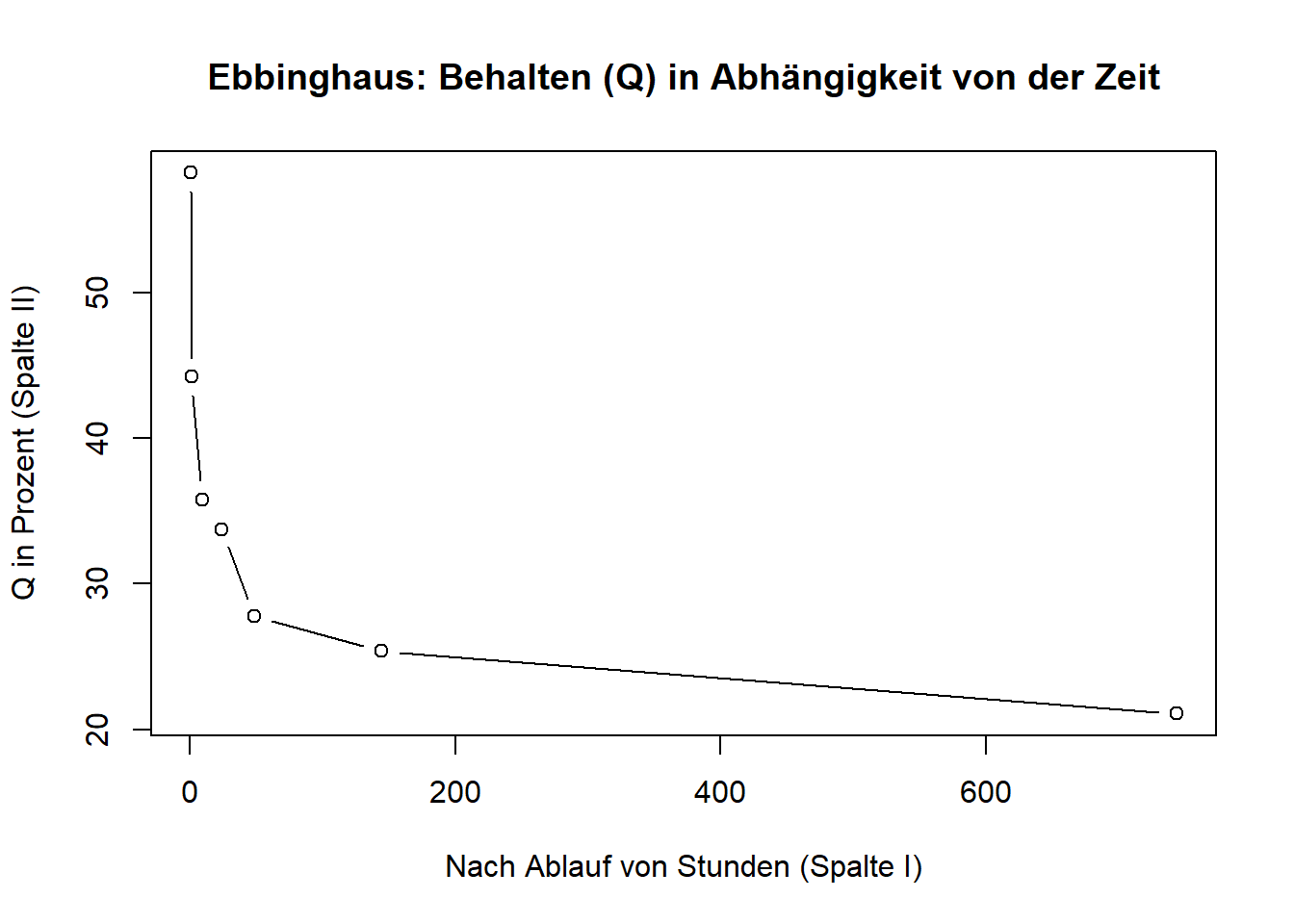
Das Wiederlernen \(WL\), das nun weniger Zeit benötigte, definierte er als Arbeitsersparnis \(D = (L − WL)\) und verwendete diese als Maß der Behaltensleistung. In Prozent umgerechnet (Q) gibt diese Ersparnis an, wie groß der Anteil des Behaltenen im Vergleich zur ursprünglichen Lernarbeit ist.
Eine entsprechende Grafik des Vergessens zeigt die typische Vergessenskurve.
Ebbinghaus versuchte, seine sieben Mittelwerte in eine “einfache” mathematische Formel zu fassen:
- \(t\) = Zeit seit dem Ende des Lernens (in Minuten),
- \(b\) = Behaltenswert in Prozent (Arbeitsersparnis beim Wiederlernen),
- \(c\) und \(k\) = Konstanten, die zur Anpassung an seine Daten gewählt werden.
\[ b(t) = \frac{100 \, k}{(\log t)^c + k} \]
Seine Schlussfolgerung: Das Vergessen folgt näherungsweise einem logarithmischen Gesetz – mit starken Anfangsverlusten und danach stetig schwächer werdenden weiteren Verlusten.
Nun sind \(c\) und \(k\) die interessierenden Parameter, die geschätzt werden sollen, damit Ebbinghaus’ Gleichung funktioniert. Hier wird deutlich, dass dieses Modell keinem linearen Modell in den Parametern entspricht, denn der Parameter \(c\) tritt als Exponent auf.
Ebbinghaus schreibt:
Setzt man für gemeine Logarithmen nach ungefährer Schätzung und ohne genauere Berechnung durch kleinste Quadrate \(k = 1,84\) und \(c = 1,25\) [ergibt sich eine gute Schätzung der Behaltensleistung.] (S. 105).
Das heißt: Er hatte seine 7 Mittelwerte und hat die Konstanten von Hand so eingestellt, dass die Formel gut zu den Punkten passt – aber ohne einen systematischen Schätzalgorithmus aufzuschreiben.
Beispiel: 1 Tag nach dem Lernen
Ein Tag hat \(24\) Stunden, also \(t = 24 \cdot 60 = 1440\) Minuten.
Wir setzen ein in:
\(v(t) = 100 - b(t)\) und \(b(t)= \frac{100 \, k}{(\log t)^c + k}\)
\[ \log_{10}(1440) \approx 3{,}158 \]
\[ \bigl(\log_{10}(1440)\bigr)^{c} = \bigl(3{,}158\bigr)^{1{,}25} \approx 4{,}21 \]
\[ b(1440) = \frac{100 \cdot 1{,}84}{4{,}21 + 1{,}84} \approx \frac{184}{6{,}05} \approx 30{,}4 \]
\[ v(1440) = 100 - b(1440) \approx 69{,}6 \]
# Parameter nach Ebbinghaus
c <- 1.25
k <- 1.84
# Behaltensfunktion b(t) in Prozent
b_fun <- function(t_min, c = 1.25, k = 1.84) {
100 * k / (log10(t_min)^c + k)
}
# Vergessensfunktion v(t) in Prozent
v_fun <- function(t_min, c = 1.25, k = 1.84) {
100 - b_fun(t_min, c, k)
}
# Beispiel: 1 Tag = 24 Stunden = 1440 Minuten
t_1tag <- 24 * 60
b_1tag <- b_fun(t_1tag)
v_1tag <- v_fun(t_1tag)
b_1tag # Behaltensleistung nach 1 Tag (≈ 30.4 %)[1] 30.41101v_1tag # Vergessensleistung nach 1 Tag (≈ 69.6 %)[1] 69.58899Laut der Modellgleichung liegt das Vergessen bei etwa 69,6% In seinen tatsächlichen Messdaten liegen die empirischen Werte bei \(t = 24\) Stunden bei ungefähr 66,3 % Vergessen. Die Gleichung ist eine gute angenäherte Beschreibung der Empirie.
4. Warum ist die Vergessenskurve ein nichtlineares Modell?
Da der Parameter \(c\) als Exponent in der Modellgleichung auftritt, ist das Modell in seinen Parametern nicht linear. Die klassische Form der Methode der kleinsten Quadrate, die auf lineare Modelle in den Parametern zugeschnitten ist und eine Lösungsformel besitzt, lässt sich deshalb nicht ohne Weiteres anwenden.
5. Ausblick: “Linearisierung”
Es ist mit einem Trick möglich, aus dem nichtlinearen Modell von Ebbinghaus ein lineares Modell zu machen. Dazu werden die beobachteten Werte geeignet transformiert.
Ausgangspunkt ist das Modell
\[ b(t) = \frac{100\,k}{(\log_{10} t)^c + k}, \]
Zunächst nutzen wir das Verhältnis von Behaltenem zu Vergessenem, dass Ebbinghaus selbst auf S. 106 angibt:
\[ \frac{b(t)}{100 - b(t)} = \frac{k}{(\log_{10} t)^c}. \]
Nun logarithmieren wir beide Seiten (mit Zehnerlogarithmus):
\[ \log_{10}\!\left(\frac{b(t)}{100 - b(t)}\right) = \log_{10} k - c \,\log_{10}\bigl(\log_{10} t\bigr). \]
Setzt man
\[ Y = \log_{10}\!\left(\frac{b}{100 - b}\right), \qquad X = \log_{10}\bigl(\log_{10} t\bigr), \]
so erhält man die lineare Beziehung
\[ Y = a + bX, \]
mit
\[ a = \log_{10} k, \qquad b = -c. \]
Durch diese Transformation der Daten (von \(b\) und \(t\) zu \(Y\) und \(X\)) wird aus dem ursprünglich nichtlinearen Modell ein lineares Regressionsmodell in den neuen Parametern \(a\) und \(b\). Aus den geschätzten Werten für \(a\) und \(b\) lassen sich anschließend die ursprünglichen Modellparameter über \(k = 10^{a}\) und \(c = -b\) zurückgewinnen.
# Transformation für lineare Regression
t_min <- stunden*60
b_obs <- Q
X <- log10(log10(t_min))
Y <- log10(b_obs / (100 - b_obs))
lm_fit <- lm(Y ~ X)
coef(lm_fit)(Intercept) X
0.258672 -1.216895 # Intercept = log10(k), slope = -c
c_hat <- -coef(lm_fit)[["X"]]
k_hat <- 10^coef(lm_fit)[["(Intercept)"]]
c_hat; k_hat[1] 1.216895[1] 1.814145Das ist beeindruckend nah an den ursprünglichen Schätzungen von Ebbinghaus (1885).
Literatur
Ebbinghaus, H. (1885). Über das Gedächtnis: Untersuchungen zur experimentellen Psychologie. Duncker & Humblot. Retrieved from https://pure.mpg.de/rest/items/item_2316418_4/component/file_2552915/content
Titz, J. (2023, May 10). Linear ist nicht gleich linear ODER Der größte Irrtum in der linearen Regression. Retrieved from https://johannestitz.com/post/2023-05-10-linearit%C3%A4t/