… besser in der 2. Liga gewinnen als in der 1. Liga verlieren?
Zuschaueraufkommen nach Auf- und Abstieg
Sport
R
Simulation
Author
Markus Burkhardt
Published
March 12, 2024
Lernziele in R
Multiple Regression
Einleitung
Letztes Wochenende war ich im ausverkauften Weserstadion und wieder einmal war ich sehr bewegt und begeistert von der Stadionatmosphäre und der Fanstimmung (und natürlich wegen eines spannenden Fußballspiels, das schließlich mit einem 1:1 endete).
Aus Sicht des Fans habe ich mich schon häufiger gefragt, ob nicht der Sieg meiner Mannschaft für die Stadionatmosphäre wichtiger wäre als die Liga oder anders formuliert: “Ist es besser in der 2. Liga zu gewinnen als in der 1. Liga zu verlieren?”
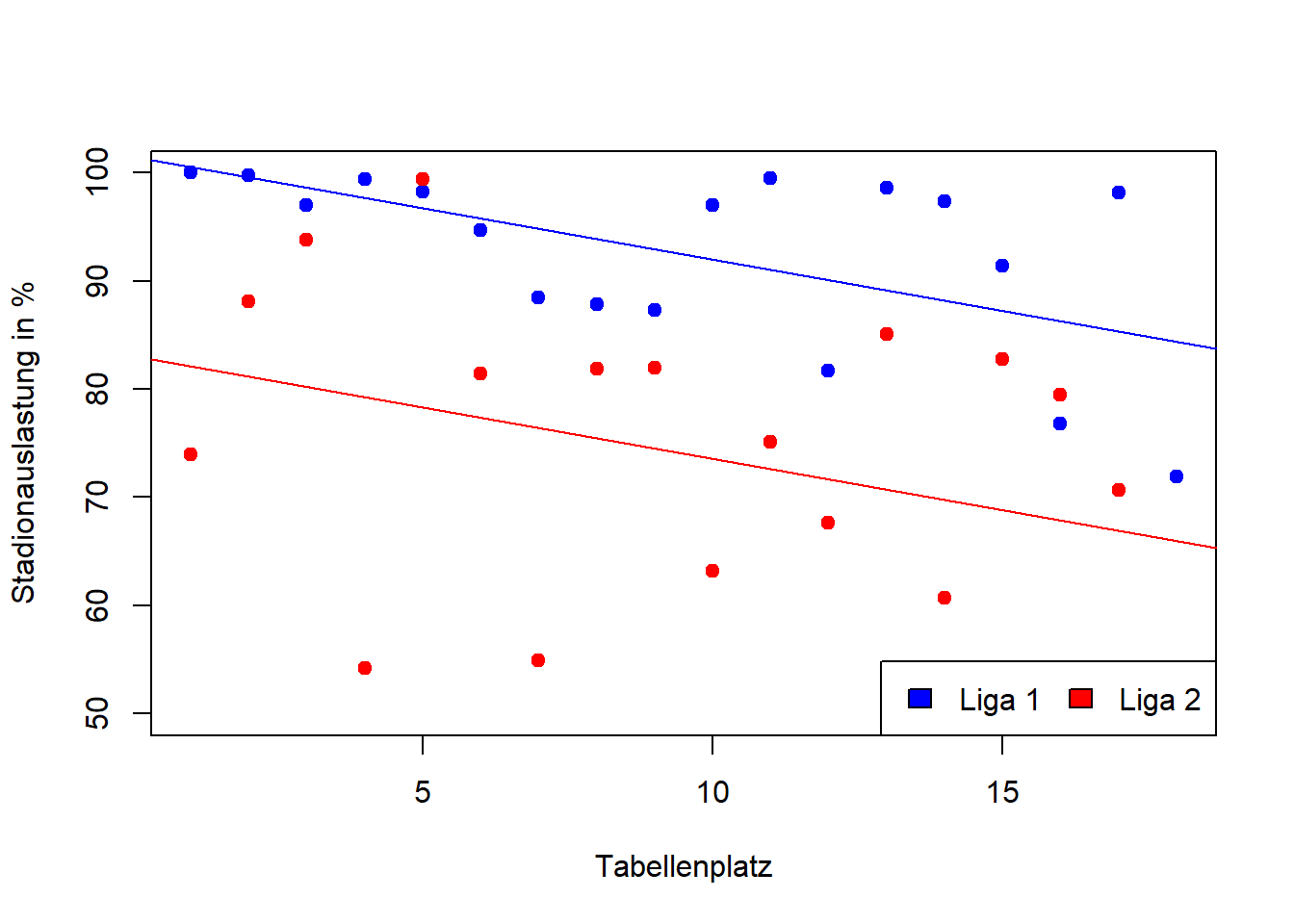
Glücklicherweise lässt sich diese Frage empirisch beantworten, da auch Zuschauerstatistiken öffentlich zugänglich sind1. Ich analysierte in einer ersten Exploration den Zusammenhang zwischen Stadionauslastung und Tabellenplatz der Saison 2022/2023.
Vorhersage der Stadionauslastung mit einem linearen Modell
(In diesem Modell ist die jeweilige Liga mit den Werten 1 und 2 kodiert.)
Die prozentuale Auslastung sinkt mit jedem Platz, den eine Mannschaft in der Tabelle nach unten rutscht, um ca. 1%-Punkt (\(b = -0,95\)). In der 2. Bundesliga ist die Stadionauslastung um ca. 20%-Punkte (\(b = -18,4\)) geringer als in der 1. Bundesliga. Interessant sind auch die \(\beta\)-Gewichte. Für die Vorhersage der Auslastung ist die Zugehörigkeit zur Liga in etwa doppelt so wichtig wie der Tabellenplatz und mit \(R^2=0,48\) haben wir ein ziemlich gutes Model vorliegen.
Liga1 <-1:18Liga2 <-19:36plot(Zuschauer_2022$Pl.[Liga1], Zuschauer_2022$Auslastung[Liga1],pch =19, col ="blue", ylim =c(50,100), ylab ="Stadionauslastung in %", xlab ="Tabellenplatz")abline(a =101.5, b =-0.95, col ="blue")points(Zuschauer_2022$Pl.[Liga2], Zuschauer_2022$Auslastung[Liga2],pch =19, col ="red")abline(a =83.1, b =-0.95, col ="red")legend("bottomright", legend =c("Liga 1", "Liga 2"), fill =c("blue", "red"), horiz = T)
Wir können das Modell noch systematisch verbessern. Hierzu werde ich noch gesondert einen kleinen Beitrag schreiben, da wir für unsere kleine Exploration einige Voraussetzungen gemacht haben, die möglicherweise gar nicht erfüllt sind. Trotzdem ist das lineare Modell ein gutes statistisches Mittel, um einen ersten Eindruck zu unserer Fragestellung zu gewinnen.
Die Hypothese war:
… besser in der 2. Liga gewinnen, als in der 1. Liga verlieren?
Die Vorhersage für zwei Extremfälle zeigt allerdings:
Tabellenplatz in der 1. Bundesliga \(\hat{y}_{Auslastung}= 84,4 \%\)
Tabellenplatz in der 2. Bundesliga \(\hat{y}_{Auslastung}= 82,2 \%\)
Für die Stadionauslastung ist es also besser, in der Bundesliga zu spielen - das hatte ich so nicht erwartet.
Quasi-experimentelles-Design
Nun lässt sich gut argumentieren, dass die Analyse einer Absschlusstabelle viele Faktoren der Stadionauslastung unberücksichtigt lässt. Angefangen von der Einwohnerzahl der Stadt über die Stadiongröße bis hin zur Tradition und Fankultur des jeweiligen Vereins. Aus den Daten der letzten Jahre können wir ein kleines Quasi-Experimentelles-Design “basteln”. Als UV haben wir 3 Ausprägungen:
Aufstieg (Auf)
Abstieg (Ab)
Verbleib in der Liga (z. B. nach Relegation) (V)
Betrachten wir die Saisons von 2009/10 bis 2018/19, haben wir eine kleine Stichprobe. Unser Kriterium ist diesmal die Veränderung der Auslastung bezüglich einer Saison \(t_0\) und der folgenden Saison \(t_1\). Dabei unterscheiden wir, ob es einen Aufstieg, Abstieg oder Verbleib in der jeweiligen Liga gab (Folge) und die Veränderung des Tabellenplatzes. Das Gute an diesem Design ist, dass wir den Einfluss aller anderen Variablen konstant halten. Die Erklärungskraft des Modells, sollte dadurch steigen.
Wir bereiten den Datensatz vor:
Zuschauer_QE <-read_delim("https://www-user.tu-chemnitz.de/~burma/blog_data/Auf_Ab_Verbleib.csv", delim =";", escape_double =FALSE, locale =locale(decimal_mark =",", encoding ="ISO-8859-1"), trim_ws =TRUE)# Berechnung der Veränderungen (Differenzen)QE <-data.frame(Auslastung_D = Zuschauer_QE$F_Auslastung - Zuschauer_QE$Auslastung,Folge =factor(Zuschauer_QE$UV, levels =c("V", "Ab", "Auf")),# Andersherum Subtrahiert da hohe Tabellenplätze schlecht sind.Tabelle_D = Zuschauer_QE$Pl - Zuschauer_QE$FS_Pl )# Berechnung des Modellsmodel2 <-lm(Auslastung_D ~ Folge + Tabelle_D , data = QE)tab_model(model2, show.se = T, show.ci = F, show.std = T)
Auslastung_D
Predictors
Estimates
std. Error
std. Beta
standardized std. Error
p
(Intercept)
-0.99
2.33
-0.11
0.14
0.672
Folge [Ab]
-17.47
4.04
-1.07
0.25
<0.001
Folge [Auf]
22.21
3.91
1.36
0.24
<0.001
Tabelle D
0.38
0.22
0.27
0.15
0.089
Observations
60
R2 / R2 adjusted
0.690 / 0.674
Mein erster Blick fiel auf die Modellgüte \(R^2 = 0,69\) (!). Auch das hätte ich nicht erwartet. Die quasi-experimentelle Kontrolle führt zu einer deutlich größeren Varianzaufklärung. (Natürlich lassen sich model1 und model2 nicht direkt vergleichen, aber dennoch ist diese Veränderung wirklich beachtlich!)
Interpretieren wir nun die Regressionskoeffizienten der Reihe nach. Die Referenz der Analyse bilden jene Vereine, die in der entsprechenden Liga verbleiben. Diese Vereine verzeichnen statistisch gesehen einen minimalen Rückgang der Stadionauslastung um durchschnittlich 1% (wobei dieser Veränderung nicht signifkant ist (\(H_0: b = 0\)). Bei einem Abstieg verringert sich die Auslastung um 17,5%-Punkte, bei einem Aufstieg erhöht sich die Stadionauslastung um 22,21 %-Punkte. Ist man in der Nachfolgesaison einen Platz besser, dann steigt auch die Stadionauslastung um 0,38 %-Punkte.
Eine “kleine” Prognose
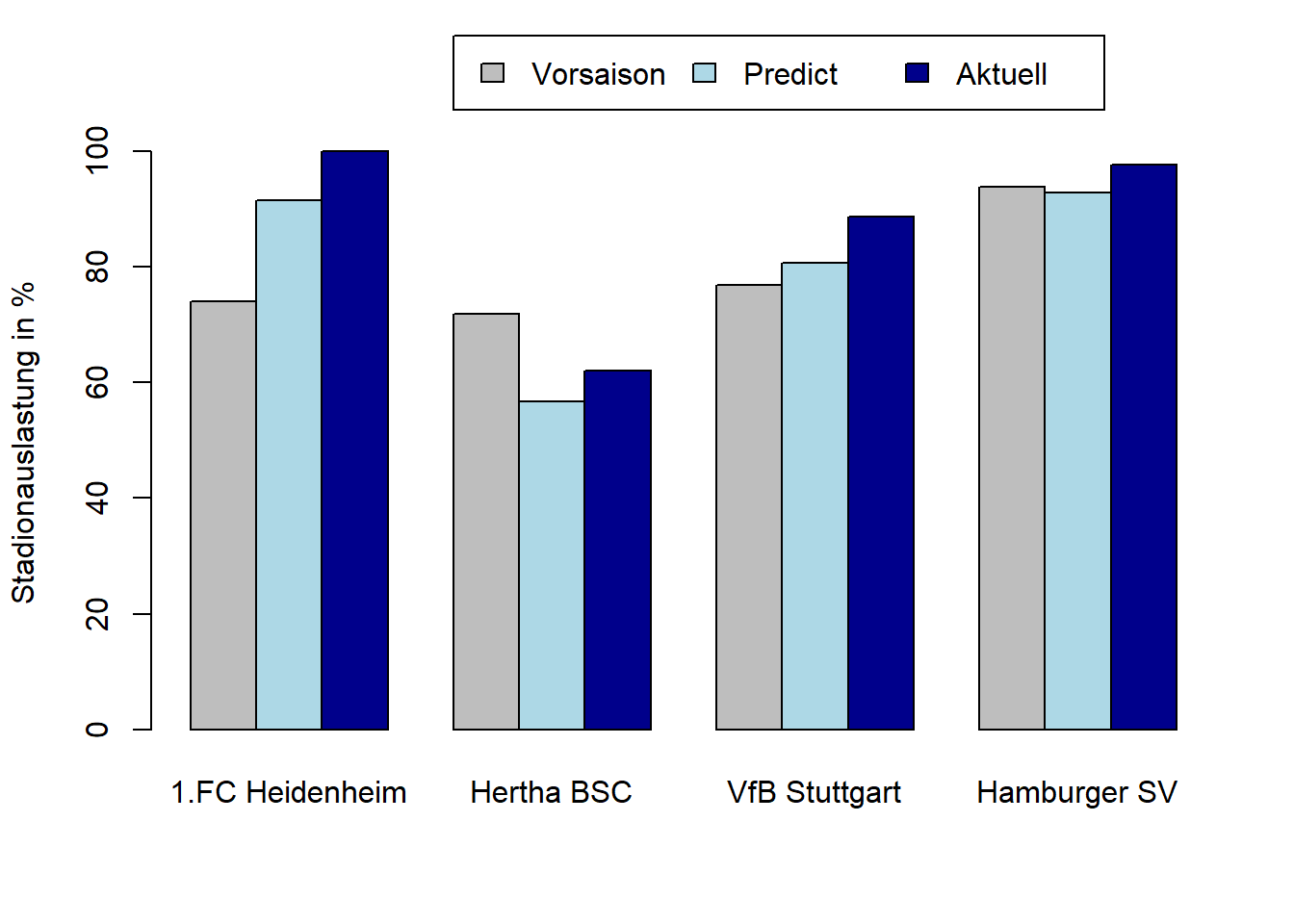
Betrachten wir exemplarisch 4 Vereine:
1.FC Heidenheim (Aufsteiger)
Hertha BSC (Absteiger)
VfB Stuttgart (Verbleib in der 1. Liga)
Hamburger SV (Verbleib in der 2 Liga)
Stand heute (24. Spieltag) wagen wir eine Zuschauerprognose und nutzen den aktuellen Tabellenplatz.
In der Grafik ist ersichtlich, dass der hellblaue Balken (Prognose) viel näher am dunkelblauen Balken (aktuelle Auslastung) ist als der graue Balken (mit Ausnahme des HSV; hier beträgt der Unterschied nur 1 Prozentpunkt bei ohnehin sehr hoher Auslastung).
Fazit
Für die Auslastung des Stadions lohnt es für einen Verein immer höherklassig zu spielen (zumindest für 1. und 2. Bundesliga). Eine weitere wichtige Einflussgröße ist der Tabellenplatz, also der sportliche Erfolg eines Teams, wenn gleich dieser deutlich geringer ist (ca. 1/5). Meine eigene Wahrnehmung, “… besser in der 2. Liga gewinnen als in der 1. Liga verlieren” lässt sich empirisch nicht verallgemeinern.
Footnotes
Ich habe mir hier die Daten von transfermarkt.de angeschaut. Interessanterweise sind diese nicht komplett mit anderen Datenbanken z. B. fusballdaten.de identisch.↩︎