Wie sinnvoll sind Spielstatistiken: Spieltag 26 - ein atheoretischer Ansatz
Theorie
R
Sport
Author
Markus Burkhardt
Published
March 27, 2024
Lernziele
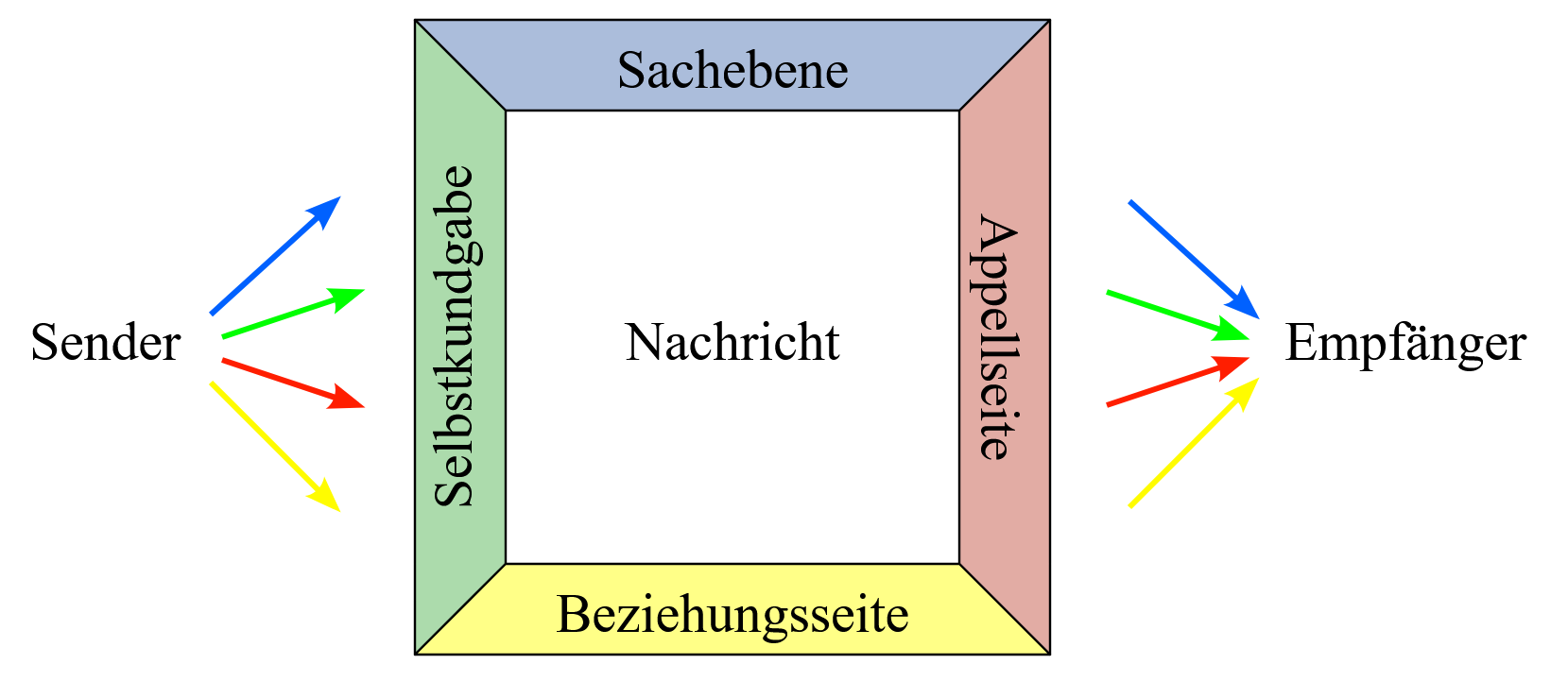
Das 4-Seitenmodell der Kommunikation
Argumente für statistische Prognosen
Team-Statistiken sind im Sport allgegenwärtig:
Team-Statistiken sind im Sport allgegenwärtig und Kommentator:innen werden nicht müde, im Fernsehen oder im Streaming die verschiedensten Statistiken aufzusagen.
Aussagen wie:
“Bei den letzten zehn Aufeinandertreffen der Teams A und B gab es nur 2 Siege für A und der letzte Sieg liegt 25 Jahre zurück.”
Faktisch mag diese Aussage richtig sein, aber welches Ziel verfolgen Komentator:innen mit dem Ansagen solcher Statistiken?
Analyse der Kommunikation
Versuchen wir uns an einer kleinen Kommunikationspsychologischen Analyse und betrachten die Nachricht mit dem 4-Seiten-Modell von Schulz von Thun (2013).
Sinngemäß sagte der Kommentator im DFB-Pokal-Viertelfinale:
“Es gab 10 Aufeinandertreffen von Saarbrücken und Mönchengladbach. Der letzte Sieg von Saarbrücken liegt 32 Jahre zurück.”
Sachebene:
“Spiele beider Mannschaften haben eine lange Tradition. Insgesamt gewann Mönchengladbach mehr Spiele als Saarbrücken und ist faktisch die erfolgreichere Mannschaft im Zusammentreffen (über die letzten Jahrzehnte).”
Selbstkundgabe (mit Appell):
“Ich bin ein Kenner der Fußballhistorie und gut vorbereitet. Sie können mir und meiner Expertise vertrauen.”
Beziehungsseite:
“Ich bin Experte – Sie sind Zuschauer. Ich informiere und unterhalte Sie. (Ich „bestimme“ die einseitige Kommunikation.)”
Appelseite:
“Bleiben Sie dran, um zu sehen, ob der Underdog es vielleicht doch schafft, denn Gladbach wird wahrscheinlich gewinnen.”
Exemplarische Analyse am Beispiel
Heute trifft mit Heidenheim das Überraschungsteam mit den meisten Sprints auf Stuttgart, die zweite Überraschungsmannschaft der Saison, die die drittstärkste Passquote aufweist. Es wird also spannend!
So oder so ähnlich könnte eine Anmoderation klingen. Auf der Appellebene heißt das: “Schauen Sie das Spiel an und hören Sie mir zu - es wird spannend!”
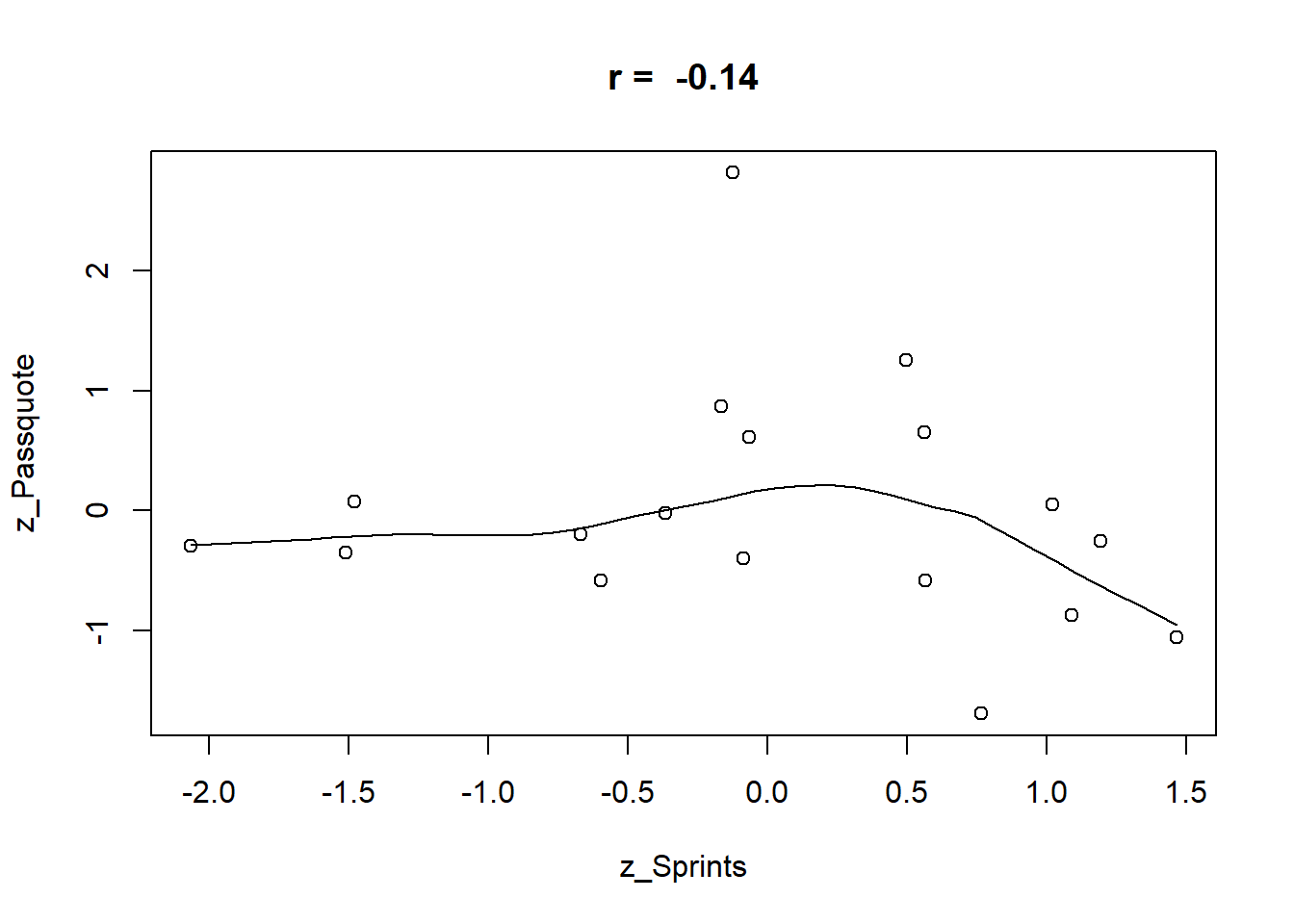
Versuchen wir den kommenden 27. Spieltag anhand von Passquote und Sprints vorherzusagen. Zunächst berechnen wir die \(z\)-standardisierten Variablen und bilden die Summe aus Sprint und Passquote für jede einzelne Mannschaft und betrachten die Pearson-Korrelation \(r\).
Der kleine Zusammenhang ist hier erwünscht, denn es bedeutet, dass die Variable nahezu unabhängig voneinander sind. Betrachten wir die Ansetzungen und den entsprechenden “Pass-Sprint-Score” (PSS).
# Heimheim <-c(5,1, 6,12,10,2,7,3,15)gast <-c(16, 8,13, 9,14,4,17,11,18)S27 <-cbind(1:9, team_stats[heim, 1:2], PSS[heim], team_stats[gast, 1:2], PSS[gast])# H für Heim; G für Gastcolnames(S27) <-c("Partie_Nr" , "Tab_H", "Mannschaft_H", "PSS_H", "Tab_G", "Mannschaft_G", "PSS_G")S27
Wir prognostizieren, dass die Mannschaft mit dem höheren \(z\)-Wert gewinnt. Zum Vergleich sagen wir den Spielausgang ganz simpel mit dem Tabellenplatz vorher (wir verzichten auf Unentschieden, also betrachten nur Siege und Niederlagen als Spielausgang. Zusätzlich habe ich noch die Quoten bei einem Wettanbieter nachgeschaut - möglicherweise nutzt dieser auch meinen theoriefreien “Pass-Sprint-Score”.1 😉
Prognose_PSS Prognose_Tab Prognose_Wette
1 RB Leipzig RB Leipzig RB Leipzig
2 Bayer 04 Leverkusen Bayer 04 Leverkusen Bayer 04 Leverkusen
3 Eintracht Frankfurt Eintracht Frankfurt Eintracht Frankfurt
4 Borussia Mönchengladbach SC Freiburg Borussia Mönchengladbach
5 VfL Wolfsburg SV Werder Bremen VfL Wolfsburg
6 FC Bayern München FC Bayern München FC Bayern München
7 FC Augsburg FC Augsburg FC Augsburg
8 VfB Stuttgart VfB Stuttgart VfB Stuttgart
9 VfL Bochum VfL Bochum VfL Bochum
Es gibt leider nur 2 Ausgänge, die in unserem Beispiel differenzieren. Das sind die Ansetzungen 4 und 5. Daraus lässt sich natürlich noch keine Passung des Algorithmus ableiten. Daher warten wir den 27. Spieltag ab und wiederholen unserer Vorhersage dann noch einmal.
Nun sind wir aus lauter Leidenschaft ein bisschen in die Daten eingestiegen. Eigentlich möchte ich aber 3 Argumente ansprechen, die für die Anwendung von Team-Statistiken zur Prognose wichtig sind.
Sind die angeführten Variablen überhaupt relevant bzw. was bedeuten sie?
Gibt es eine sinnvolle Erklärung / Theorie für die Wirkung der Variablen - oder handelt es sich um Post-Hoc Erklärungen?
Lassen sich die vielen Kontextfaktoren - also die Bedingungen, unter denen die statistischen Kennwerte erhoben wurden, auf die Bedingungen der Prognose übertragen?
Anwendung auf unser Beispiel:
Auf der Website der Bundesliga finden wir keine Information darüber, was eigentlich ein Sprint ist. Folglich fehlt die Definition des gemessenen Konstrukts, das macht natürlich theoretische Ableitungen unmöglich. (Vielleicht halten sich die Datenanalysten bzw. die Bundesliga bewusst bedeckt - denn mit klaren Definitionen wären die angegebenen Zahlen ja validierbar.)
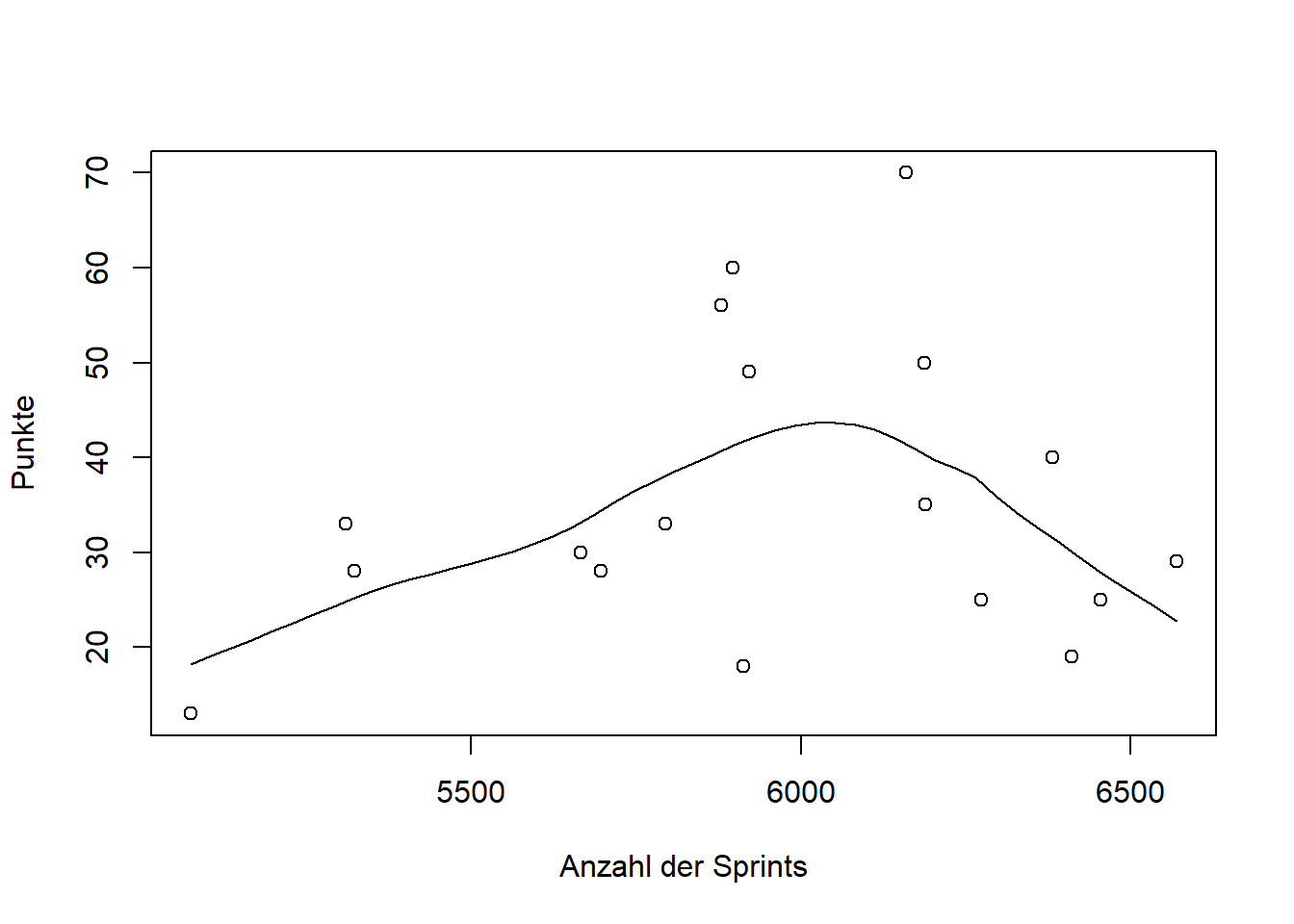
Immerhin findet sich in einem Online-Lexikon eine Definition. Eine Geschwindigkeit > 30 km/h gilt als Sprint. Besitzt diese Statistik (Sprints) aber auch eine Relevanz? Für sich genommen wohl kaum, wie der Zusammenhang von \(r = 0.17\) und \(R^2=2.89\%\) zeigt.
scatter.smooth(team_stats$Sprints, team_stats$Pkt.,ylab ="Punkte", xlab ="Anzahl der Sprints")
Hier könnten wir noch ein bisschen “Curve-Fitting” betreiben, um die Erklärungskraft zu erhöhen - aber das sollten wir natürlich niemals(!) tun. Der Grund ist das zweite Argument. Es gibt keine sinnvolle theoretische Erklärung. Natürlich fällt uns Post-Hoc eine Erklärung ein. Wenig Sprints sind schlecht, weil es keine Tore aus Kontersituationen gibt und viele Sprints sind schlecht, weil man dann immer in der Abwehr hinterherläuft. Die Betrachtung dieser einzelnen Variablen vernachlässigt den Kontext (Argument 3). Sprinten ist immer in ein Spielsystem und die Taktik des Gegners eingebettet. Die einzelne Statistik mag vielleicht mit dem Ausgang eines Spieles korrelieren, vielleicht ist sie aber “nur” ein Kovariat. Das macht die Analyse nicht sinnlos, aber es ist inhaltlich fragwürdig, eine Prognose darauf zu stützen.
Literatur
Schulz von Thun, Friedemann (2013). Miteinander reden 1: Störungen und Klärungen: Allgemeine Psychologie der Kommunikation. Vol. 1. Rowohlt Verlag
Footnotes
Bitte auf das Wetten verzichten! Die statistisch gut vorhersagbaren Ansetzungen haben bei der Gewinnausschüttung einen zu geringen Gewinn, um die Fehleinschätzungen von “unsicheren” Spielen auszugleichen. Bei Gelegenheit schreibe ich dazu einmal einen eigenen Beitrag. Es gilt wie bei allen Glücksspielen: Am Ende gewinnt immer die Bank!↩︎