 |
\(\%\) | \(Pct^2\) | | |  |
\(\%\) | \(Pct^2\) | |
|---|---|---|---|---|---|---|---|
| Angst | 2 | 20 | 400 | | | 1 | 12.5 | 156.25 |
| Ärger | 0 | 0 | 0 | | | 0 | 0 | 0 |
| Ekel | 4 | 40 | 1600 | | | 0 | 0 | 0 |
| Freude | 0 | 0 | 0 | | | 0 | 0 | 0 |
| Trauer | 0 | 0 | 0 | | | 0 | 0 | 0 |
| Überraschung | 4 | 40 | 1600 | | | 7 | 87.5 | 7656.25 |
Motivation
Verschiedene Emojis werden sehr unterschiedliche Emotionen zugeschrieben (siehe Titelbild).
Betrachten wir exemplarisch zwei Emojis, die Überraschung ausdrücken:
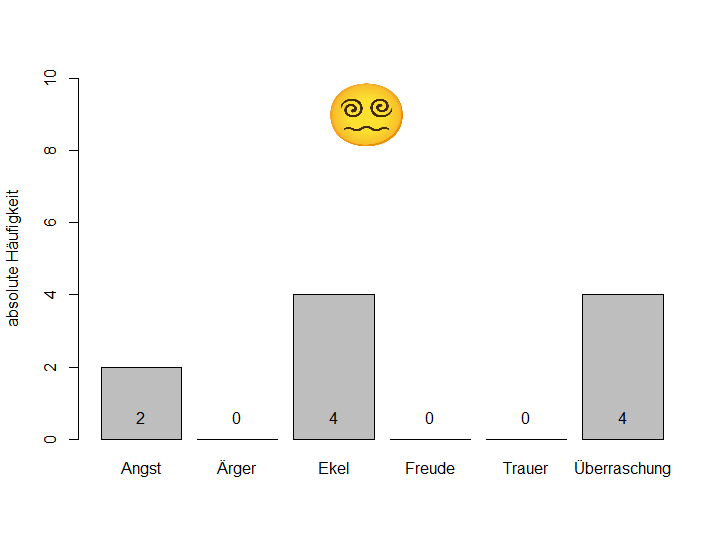
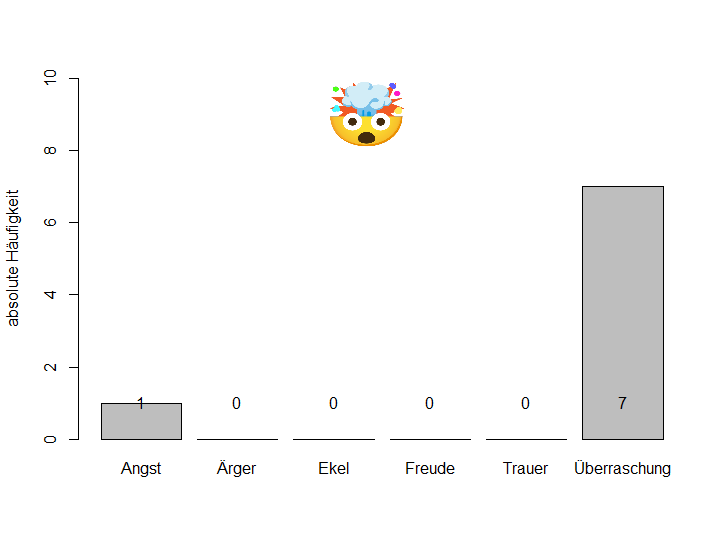
Die Streuung der Antworten auf die verschiedenen Antwortkategorien ist eine relevante Information. Im Grunde sagt sie uns, dass ein 🤯 viel sicherer interpretiert werden kann als ein 😵 , bei dem die Antworten stärker streuen. Allerdings war mir bisher kein Streuungsmaß für nominalskalierte Daten bzw. Kategorien bekannt.
Nach einer kurzen Recherche stieß ich auf zwei Streuungsmaße, die wir kurz betrachten wollen:
1 Variation Ratio \(v\) (Freeman’s Index)
\[Var_{Ratio} = 1- \frac{n_{Modus}}{N_{Gesamt}} \] \(Var_{Ratio}\) betrachtet das Verhältnis von der Anzahl der Werte, die genau den Modalwert abbilden, im Verhältnis zur Gesamtzahl. Ein \(Var_{Ratio} = 0\) bedeutet, dass keine Streuung auftritt (0 % der Daten liegen in einer anderen Kategorie als in der häufigsten Kategorie).
Für unsere beiden Emoji bedeutet das:
😵 : \(Var_{Ratio} = 1 - \frac{4}{10} = 0.60\)
🤯 : \(Var_{Ratio} = 1 - \frac{7}{8} = 0.125\)
2 Index of Qualitative Variation - IQV
\[IQV = \frac{K(100^2 - \sum{Pct^2})}{100^2(K-1)} \]
Der IQV ist ein Streuungsmaß, das das Verhältnis der Anzahl an Unterschieden in der Verteilung zu den maximal möglichen Unterschieden in der Verteilung ausdrückt, wobei \(K\) die Anzahl der Kategorien und \(Pct\) die prozentuale Kategorie darstellt. Ist der \(IQV = 1\), ist eine größtmögliche Variation vorhanden. Alle Beobachtungen verteilen sich gleichmäßig auf alle Kategorien. Bei einem \(IQV = 0\) sind alle Beobachtungen in einer Kategorie.
Für unsere beiden Emoji mit \(K = 6\) bedeutet das:
😵 : \(IQV = \frac{6*(10000 - 3600)}{50000} = 0.768\)
🤯 : \(IQV = \frac{6*(10000-(156.25 + 7656.25))}{50000} = 0.2625\)
Bewertung
Während \(v\) intuitiv verständlich ist, enthält der \(IQV\) mehr Informationen. Betrachten wir hierfür kurz folgendes Beispiel:
# Verteilung 1
VT1 <- factor(rep(LETTERS[1:5], times = c(1,2,2,4,1)), levels = LETTERS[1:5])
# Verteilung 2
VT2 <- factor(rep(LETTERS[1:5], times = c(0,0,3,4,3)), levels = LETTERS[1:5])
# ... als Grafik
par(mfrow = 1:2)
barplot(table(VT1), main = "VT1")
barplot(table(VT2), main = "VT2")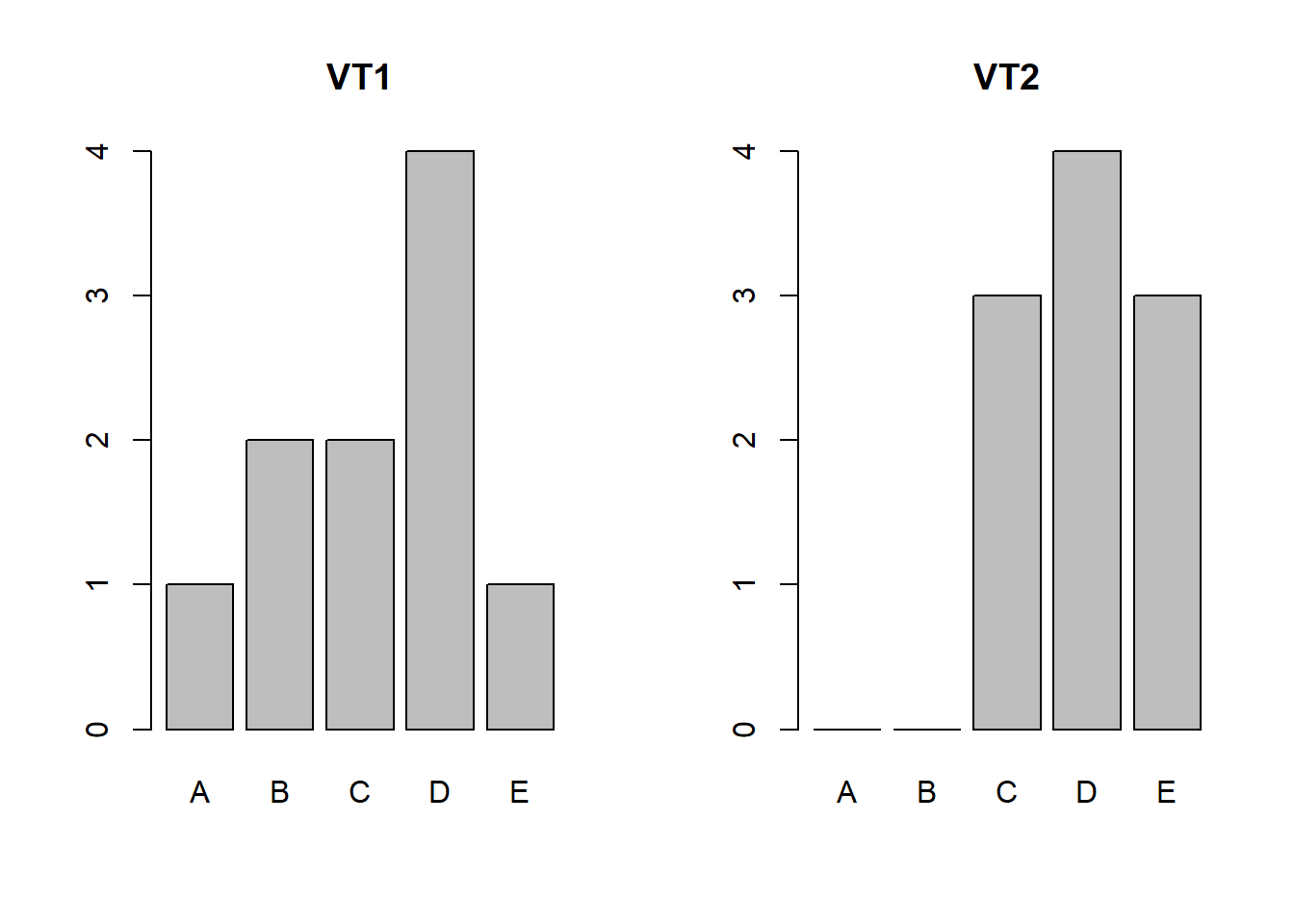
Während sich die Antworten bei Verteilung 1 (VT1) auf alle Kategorien aufteilen und somit eine größere Streuung vorhanden ist, zeigt Verteilung 2 (VT2) eine geringere Streuung, weil lediglich 3 Kategorien auftreten. Das allein muss nicht zwangsläufig in einem höheren IQV münden.
# Berechnung beider Maße
# Beide Streuungsmaße als Funktion
v_VR <- function(x) {
tab <- table(x)
1 - max(tab) / sum(tab)
}
IQV <- function(x) {
K <- length(names(table(x)))
pct <- (table(x) / sum(table(x))) * 100
IQV <- K*(10000 - sum(pct^2)) / (10000 * (K - 1))
return(IQV)
}
output <- matrix(
c(v_VR(VT1), IQV(VT1), v_VR(VT2), IQV(VT2)),
ncol = 2, dimnames = list(c("$v$", "$IQV$"), c("VT1", "VT2")))
knitr::kable(output, align = "c")| VT1 | VT2 | |
|---|---|---|
| \(v\) | 0.600 | 0.600 |
| \(IQV\) | 0.925 | 0.825 |
Literatur
Freeman, L. C., “Elementary applied statistics. new york: Johnwiley and sons,” Inc., 19t 6 (1965).
Frankfort-Nachmias, C., & Leon-Guerrero, A. (2000). Measures of variability. In Social statistics for a diverse society. Thousand Oaks, Calif: Pine Forge Press.