(Zu) niedrige Reliabilitätsschätzung in der klassische Testtheorie
Diagnostik
R
Theorie
Simulation
Author
Markus Burkhardt
Published
February 27, 2023
Lernziele in R
Simulation zur klassischen Testtheorie
Reliabilitätsbestimmung
Die KTT mit Würfeln
Eine Sache vorweg: Ich bin weder Diagnostiker noch konstruiere oder validiere ich (psychologische) Testverfahren. Doch als ich kürzlich die klassische Testtheorie (KTT) anwenden wollte, um sie auf Daten aus der Welt des Sports anzuwenden, stellte ich ernüchtert fest, dass die KTT in meinem Anwendungsfall nicht so gut funktionierte, wie ich es erhofft hatte.
Aber der Reihe nach:
Um das Problem darzustellen, bauen wir eine kleine Simulation, die nichts mit körperlicher Ertüchtigung zu tun hat (es sei denn, man möchte Würfeln als Sport bezeichnen).
1 - Die Fähigkeit eines Würfels - der True Score
Stellen wir uns vor, wir haben 5 Würfel und jeder Würfel hat auf den jeweiligen Seiten entweder eine \(1\) oder eine \(0\) aufgezeichnet. Der erste Würfel besitzt eine Seite mit einer “1”, der zweite Würfel besitzt 2 Seiten mit einer “1” und so weiter. Das Werfen der Zahl „1“ hat somit für jeden Würfel eine unterschiedliche Wahrscheinlichkeit \(p\).
In der letzten Spalte steht \(\tau\) (Tau), das genauso groß ist, wie \(p\). \(\tau\) ist in der KTT die Bezeichnung für den wahren Wert einer latenten Merkmalsausprägung. Stellen wir uns also vor, dass jeder dieser Würfel die latente Fähigkeit \(\tau\) besitzt, eine “1” zu zeigen. (Tatsächlich könnten wir einfach nachschauen und die Seiten mit einer “1” zählen, aber wir wollen einmal so tun, als ob die Fähigkeit eine latente Variable sei.)
2 - Die Schätzung des True Score eines Würfels
Was tun wir, um \(\tau\) zu schätzen? Wir würfeln und wenden die KTT an. (An dieser Stelle sei erwähnt, dass wir annehmen, dass das Ergebnis beim Würfeln tatsächlich zufällig ist und damit alle Axiome der KTT erfüllt sind!)
Wir bestimmen ein Set von 10 Items, wobei jedes dieser Items ein Wurf mit dem jeweiligen Würfel ist. Am Ende bilden wir die Summe der Würfe und - und – voilà! – erhalten eine Schätzung \(\hat{\tau}\) für jeden Würfel.
# Eine Simulationset.seed(2023)Tau <-1:5/6N <-10Tau_hat <-NULLfor (i in1:5){ Tau_hat[i] <-sum(sample(x =c(1, 0), size = N, replace = T, prob =c(Tau[i], 1- Tau[i])) )}Tau_hat /10
[1] 0.0 0.5 0.5 0.2 0.8
So richtig toll klappt das ja noch nicht! Natürlich müssten wir häufiger würfeln. Also würfeln wir 20x mit N <- 20 und erhalten:
Würfel
Seiten_mit_1
p
Tau
Tau_hat_10
Tau_hat_20
Würfel 1
1
0.167
0.167
0.0
0.20
Würfel 2
2
0.333
0.333
0.5
0.55
Würfel 3
3
0.5
0.5
0.5
0.55
Würfel 4
4
0.667
0.667
0.2
0.75
Würfel 5
5
0.833
0.833
0.8
0.80
An dieser Stelle müssen wir uns noch einmal vor Augen halten, dass wir bei unserem “Fähigkeitstest für Würfel” mit 20 perfekten Items zu tun haben. Ein Umstand, der praktisch wohl nicht erreichbar ist.
3 - \(Var(\tau)\) und \(Rel\) in der KTT
Nun steigen wir noch etwas tiefer ein in die KTT. Das Besondere ist, dass wir die Varianz von \(\tau\) schätzen können, obwohl wir lediglich \(\hat{\tau}\) kennen.
Die Grundidee ist dabei, dass wir 2 Testungen durchführen und da der Messfehler zufällig ist, können wir aus den beiden Testergebnissen \(x_p\) und \(x_q\) die Varianz und die Reliabilität bestimmen:
Wir benötigen also 2 Testergebnisse. Nichts einfacher als das! Wir würfeln im ersten Schritt 10x und im zweiten Schritt 10x und erhalten die beiden Testergebnisse \(x_p\) und \(x_q\). Anschließend berechnen wir die Varianz \(Var(\tau)\) und die Reliabilität \(Rel\).
# Eine Simulationset.seed(2023)Tau <-1:5/6N <-10Test1 <-NULLTest2 <-NULLfor (i in1:length(Tau)) { Test1[i] <-sum(sample(x =c(1,0), size = N, prob =c(Tau[i], 1- Tau[i]), replace = T) ) / N Test2[i] <-sum( sample(x =c(1,0), size = N, prob =c(Tau[i], 1-Tau[i]), replace = T) ) / N }cov(Test1, Test2); var(Tau)
[1] 0.0225
[1] 0.06944444
cor(Test1, Test2)
[1] 0.3638034
4 - Ernüchterung
Obwohl wir alle Voraussetzungen der KTT erfüllen, ist die Varianz des empirischen Ergebnisses ungefähr um den Faktor drei kleiner als die tatsächliche Varianz:
Des Weiteren wäre ein Test, dessen Reliabilität bei \(Rel = 0.36\) liegt, aus testtheoretischer Sicht wohl indiskutabel.
5 - Eine Simulation
Vielleicht liegt das Ergebnis aus Schritt 4 am Zufall? Wiederholen wir dieses Vorgehen 10 000-mal und ermitteln Median der Varianz und der Reliabilität.
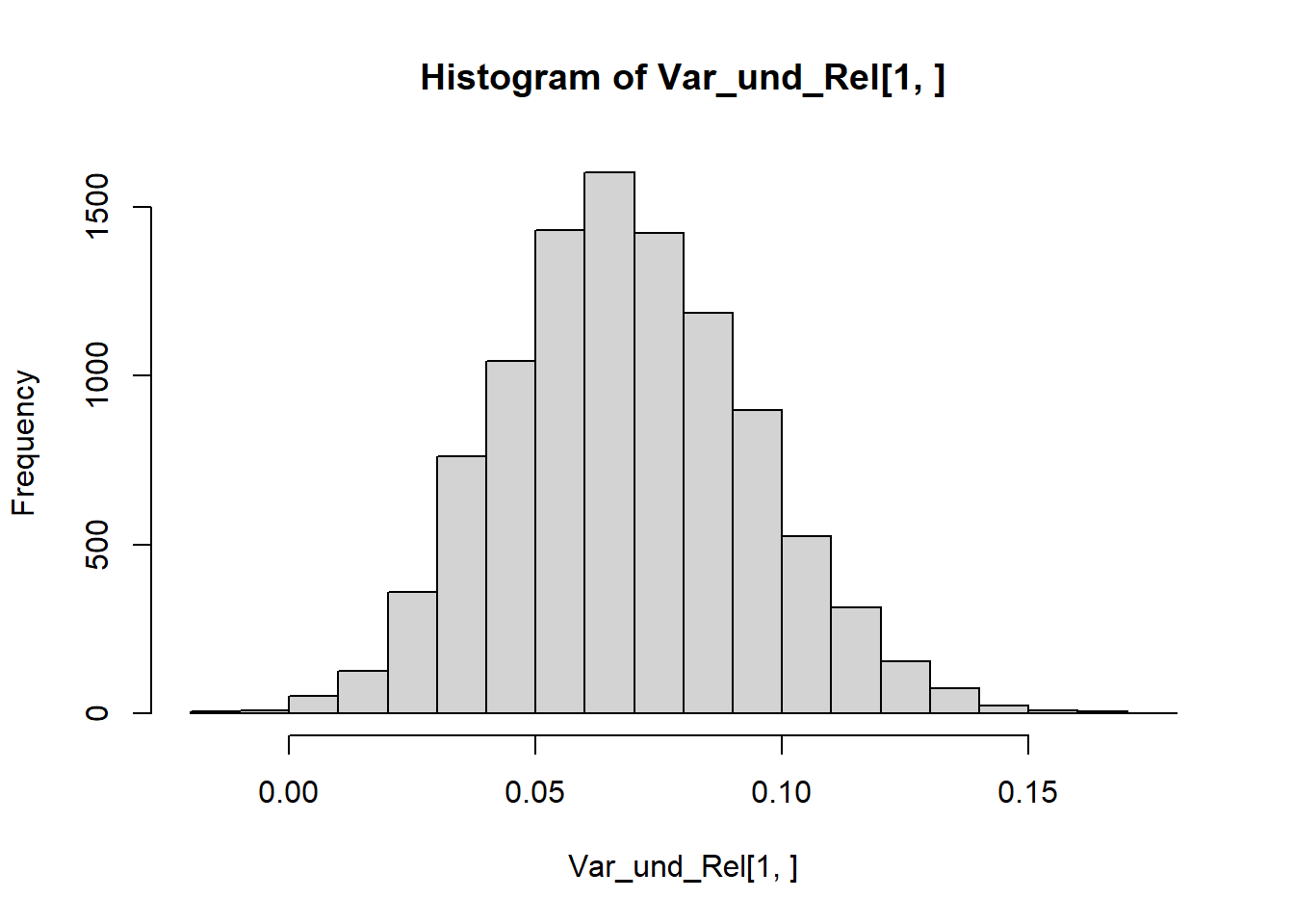
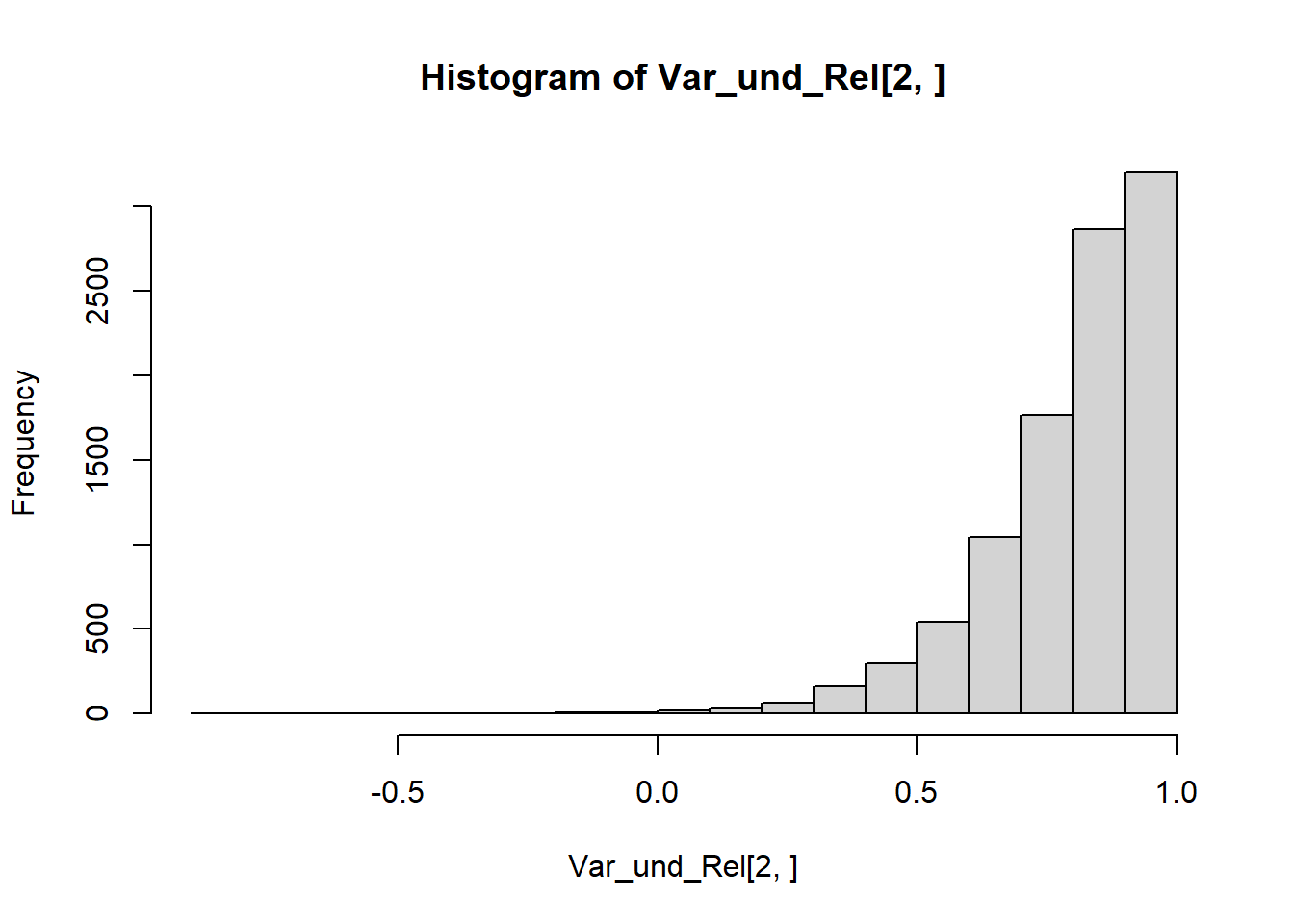
set.seed(2023)Tau <-1:5/6# Da beide Tests auf 10 Items basieren, haben wir insgesamt 20 Items.N <-10Var_und_Rel <-replicate(10000, expr = {Test1 <-NULL; Test2 <-NULLfor (i in1:length(Tau)) { Test1[[i]] <-sample(x =c(1, 0), size = N, prob =c(Tau[i], 1- Tau[i]), replace = T) Test2[[i]] <-sample(x =c(1, 0), size = N, prob =c(Tau[i], 1- Tau[i]), replace = T)}xp <-sapply(Test1, sum) / Nxq <-sapply(Test2, sum) / Nreturn(c(cov(xp, xq), cor(xp,xq)))})# Variancehist(Var_und_Rel[1 , ])
Und auch die Reliabilität ist mit \(Rel = 0.84\) deutlich größer.
Alles nur Zufall wegen eines ungünstigen set.seed()-Parameters?
Ja und Nein.
Obwohl die Varianz nun zufriedenstellend ist, bleibt die Reliabilität ein Problem. Natürlich kann man dieser erhöhen, indem die Menge der Items (im Code das N erhöht wird). Die allgemeine Formel lautet hierfür:
\[ Rel(k·\ell) = \frac{k ·Rel}{1+(k-1)·Rel}\]
wobei \(k\) der Faktor der Testverlängerung und \(\ell\) die Länge des Tests ist.
Mit unserer Simulation können wir aber auch eine Art Power-Analyse berechnen. Wie oft erhalten wir bei insgesamt \(N = 20\) Items (10 für jede Testhälfte) eine Reliabilität größer als \(Rel = .85\)
# Power Power <-sum(Var_und_Rel[2 , ] > .85) /10000Power
[1] 0.4767
In mehr als der Hälfte der Analysen würden wir unseren Fragebogen oder unsere Items infrage stellen, weil die Reliabilität zu niedrig ist, obwohl in unserem Beispiel alle Voraussetzungen der KTT erfüllt sind!
6 - Split-Half: Spearman-Brown-Korrektur
Unsere Simulation mit der Split-Half Methode stellt eine Unterschätzung der Reliabilität dar, da durch die halbierten Tests die Anzahl der Items geringer wird. Spearman und Brown schlugen (unabhängig voneinander) eine Korrektur vor: