Für eine neue Vorlesung habe ich mich noch einmal intensiver mit Effektgrößen beschäftigt. Dabei bin ich auf Hedges’ g in der „unbiased“-Variante gestoßen. In vielen R-Paketen wird dieses g (unbiased) einfach als Hedges’ g ausgegeben, ohne dass die dahinterstehende Idee besonders hervorgehoben wird. Erst beim Nachlesen des Originalartikels von Hedges (1981) wurde mir klar, warum Hedges’ g (unbiased) ein sehr gutes Abstandsmaß für Mittelwertsunterschiede ist.
Hier sind meine drei Learnings, die ich aus dem Artikel mitgenommen habe.
Learning 1: \(n -1\)
Die Verwendung von \(n − 1\) bei der Schätzung der Varianz ergibt sich laut Hedges (1981) aus der Anzahl der Freiheitsgrade, die zur Schätzung der Standardabweichung im Effektgrößenschätzer verwendet werden. Das ist zu unterscheiden von der oft anzutreffenden Idee, der Faktor \(n - 1\) sei der Populationsschätzer der Varianz. Entscheidend ist, dass der Erwartungswert von *\(g\) direkt von den Freiheitsgraden \(df = m = n_1 + n_2 - 2\) abhängt.
Learning 2: \(g\) vs. \(d\)
\(Hedges : g\) erweitert \(Glass : \delta\) – Cohen wird gar nicht zitiert. Cohen (1961) ist vor allem an der Berechnung von Power interessiert, während Hedges eher Metaanalysen im Blick hat.
Learning 3: \(g^*\) bevorzugen
Das Ausmaß des Bias spricht dafür, Hedges’ \(g^{*}\) als bevorzugtes Abstandsmaß zu verwenden.
Aktueller Stand in unserer Formelsammlung
Sedlmeier und Renkewitz, ab 2008:
Cohens \(d\):
\(d = \frac{\bar{x}_A - \bar{x}_B}{s_{AB}}\)
mit
\(s_{AB} = \sqrt{\frac{(n_A)s_A^2 + (n_B)s_B^2}{n_A + n_B }}\)
Hedges \(g\):
\(g = \frac{\bar{x}_A - \bar{x}_B}{\sigma_{AB}}\)
mit
\(\sigma_{AB} = \sqrt{\frac{(n_A - 1)\sigma_A^2 + (n_B - 1)\sigma_B^2}{n_A + n_B - 2}}\)
Hedges \(g_{unbiased} = g^{*}\) (NEU)
\({\displaystyle g^{*}=J(n_{1}+n_{2}-2)g\approx \left(1-{\frac {3}{4\cdot df-1}}\right)g}\)
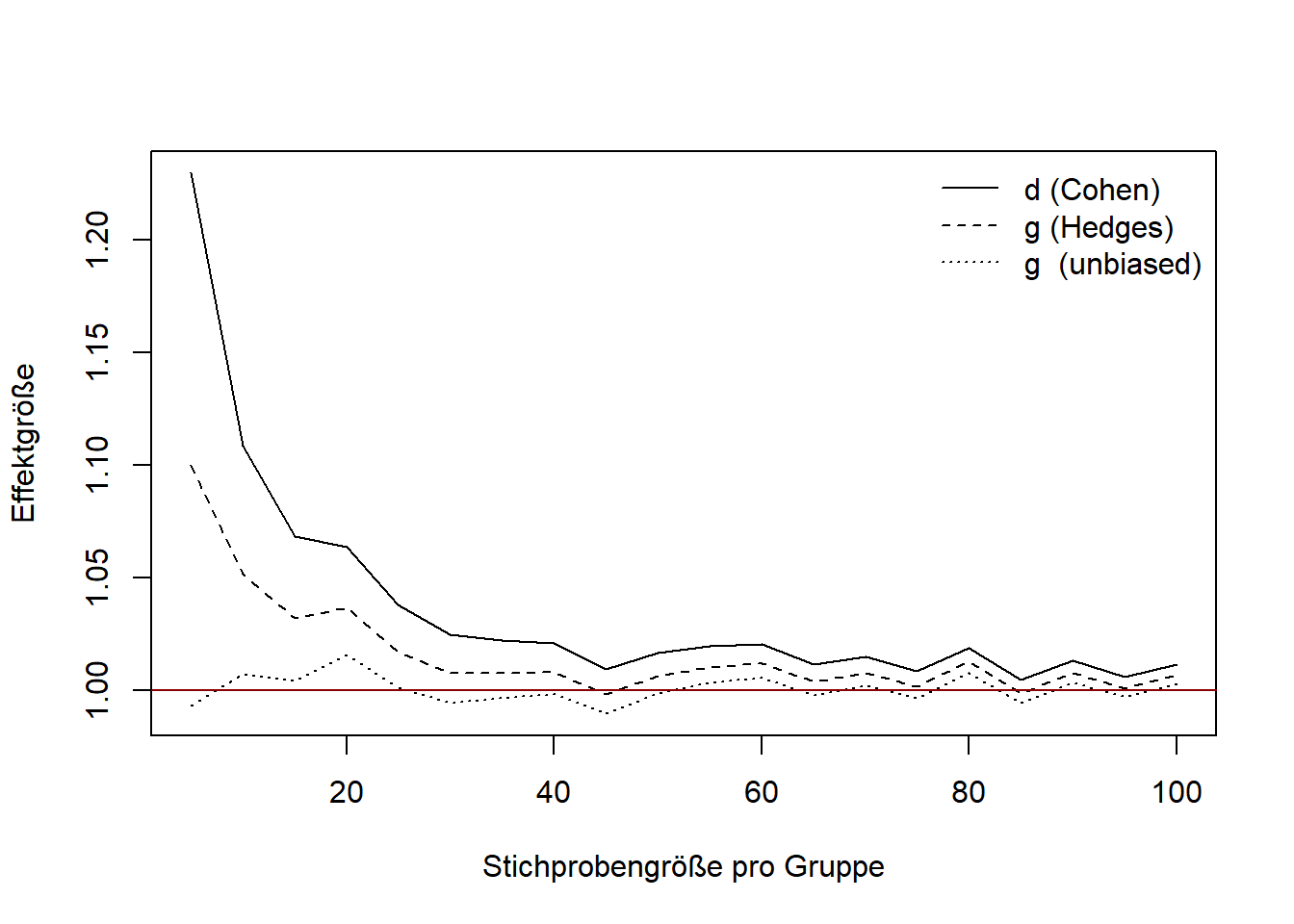
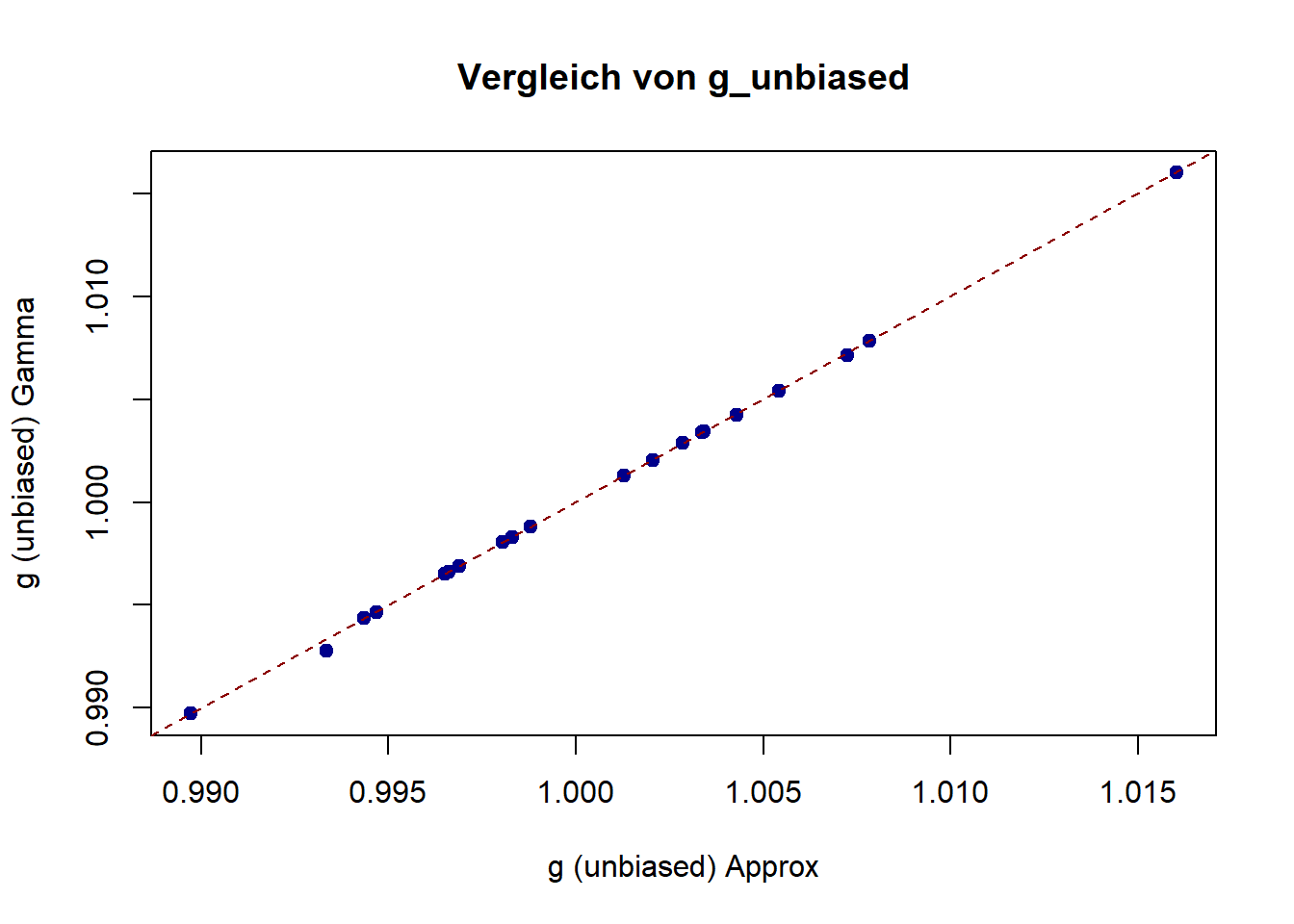
Eine Simulation mit einem Effekt von \(\delta = 1\) und normalverteilten Populationen, zeigt bei kleinen Stichproben die fehlerhafte Schätzung von \(d\) und \(g\). Hedges \(g^*\) ist unverzerrt. Im Plot zeige ich nur eine Kurve für \(g_{\text{unbiased}}\), da sich die Gamma-basierte Version (\(g_\text{unbias2}\)) und die approximative Version (\(g_\text{unbias}\)) in der Praxis kaum unterscheiden; beide liegen faktisch auf derselben Linie.
Hedges zeigt auf Seite 111, dass das \(J(n_{1}+n_{2} - 2)\) aus einer Gammafunktion hergeleitet werden kann, und er schreibt:
An accurate approximation for c(m) [c ist unser J] can be derived which is satisfactory for most applications. This approximation has the virtue that it can be computed algebraically when using packaged computer programs. The approximation is \(c(m) \approx 1 - \frac{3}{4m - 1}\)
Wir können in R ganz einfach die Gammafunktion benutzen und sind nicht auf die Approximation angewiesen.
\[c(m) = J(n_{1}+n_{2} - 2) =J(df) = \frac{\Gamma\!\left(\frac{df}{2}\right)}{\sqrt{\frac{df}{2}} \,\Gamma\!\left(\frac{df - 1}{2}\right)}, \quad df = n_{1} + n_{2} - 2\]
J <- function(m){
gamma(m / 2) / (sqrt(m / 2) * gamma((m - 1) / 2))
}
Im Plot 1 (oben) zeige ich nur eine Kurve für \(g_{\text{unbiased}}\), da sich die Gamma-basierte Version (\(g_\text{unbias2}\)) und die approximative Version (\(g_\text{unbias}\)) in der Praxis kaum unterscheiden; beide liegen faktisch auf derselben Linie.
Literatur
Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Routledge.
Hedges, L. V. (1981). Distribution theory for Glass’s estimator of effect size and related estimators. Journal of Educational Statistics, 6(2), 107–128. https://doi.org/ 10.3102/10769986006002107