Was man nicht tun sollte (obwohl es verlockend ist)
Theorie
R
Author
Markus Burkhardt
Published
April 2, 2024
Lernziele
Curve-Fitting mit poly
Unterschied zwischen guter Datenpassung und guter Vorhersage
Overfitting am Beispiel von Sprints zur Prognose der Bundesliga-Tabelle
Curve Fitting
Mit geeigneten Polynomen kann man vorhandene Daten fast beliebig gut treffen. Das sieht beeindruckend aus und führt zu hohen Werten von \(R^2\). Für echte Vorhersagen ist das aber oft wertlos oder sogar schädlich.
Ohne Theorie im Hintergrund wird Curve-Fitting schnell zu Overfitting: Das Modell beschreibt vor allem den Zufall in den Trainingsdaten und scheitert, sobald neue Daten ins Spiel kommen.
Unter Curve-Fitting versteht man umgangssprachlich die Anpassung einer mathematischen Funktion (oft eines Polynoms) an vorhandene Daten.
Beim Curve-Fitting sucht man direkt nach der Funktion, die die gegebenen Daten möglichst gut beschreibt. Das widerspricht einer theoriegeleiteten Vorgehensweise, bei der zuerst eine inhaltliche Erwartung formuliert und daraus ein Modell abgeleitet wird, das dann an Daten geprüft wird.
Curve Fitting:
Daten -> polynome Funktion
Theoriegeleitet:
inhaltliche Annahme → Modell (oft einfach, z. B. linear) → Daten
Curve-Fitting kann in der Exploration hilfreich sein, ersetzt aber niemals eine theoretische Einbettung.
Beispiel “Sprints” in der Bundesliga
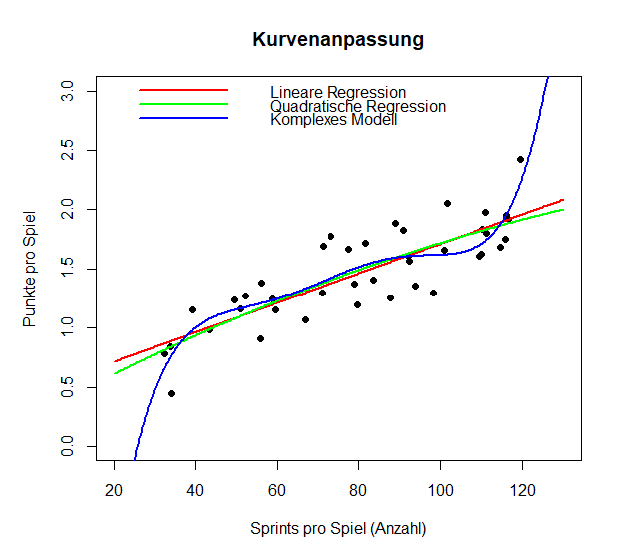
Um die Koeffizienten später besser vergleichen zu können, berechnen wir zunächst die durchschnittlichen Punkte pro Spiel und die durchschnittlichen Sprints pro Spiel. Anschließend zeichnen wir ein Streudiagramm mit einer Loess-Kurve.
Mit der Funktion poly und das Argument degree können wir in R die entsprechende Funktion erzeugen. Für degree = 1 ergibt sich die bekannte lineare Regressionsgerade:
model_grad1 <-lm(Pkt_24 ~poly(Sprints_24, degree =1), data = sprints24)model_grad2 <-lm(Pkt_24 ~poly(Sprints_24, degree =2), data = sprints24)model_grad3 <-lm(Pkt_24 ~poly(Sprints_24, degree =3), data = sprints24)model_grad4 <-lm(Pkt_24 ~poly(Sprints_24, degree =4), data = sprints24)model_grad10 <-lm(Pkt_24 ~poly(Sprints_24, degree =10), data = sprints24)# R2R2 <-c(summary(model_grad1)$r.squared, summary(model_grad2)$r.squared,summary(model_grad3)$r.squared, summary(model_grad4)$r.squared,summary(model_grad10)$r.squared)
Die Varianzaufklärung der quadratischen Funktion steigt von 3% auf fast 29%. Das Modell 10. Grades ist natürlich noch besser, aber definitv keine einfachere Beschreibung des Zusammenhangs. Wir halten es zum Vergleich im “Rennen”.
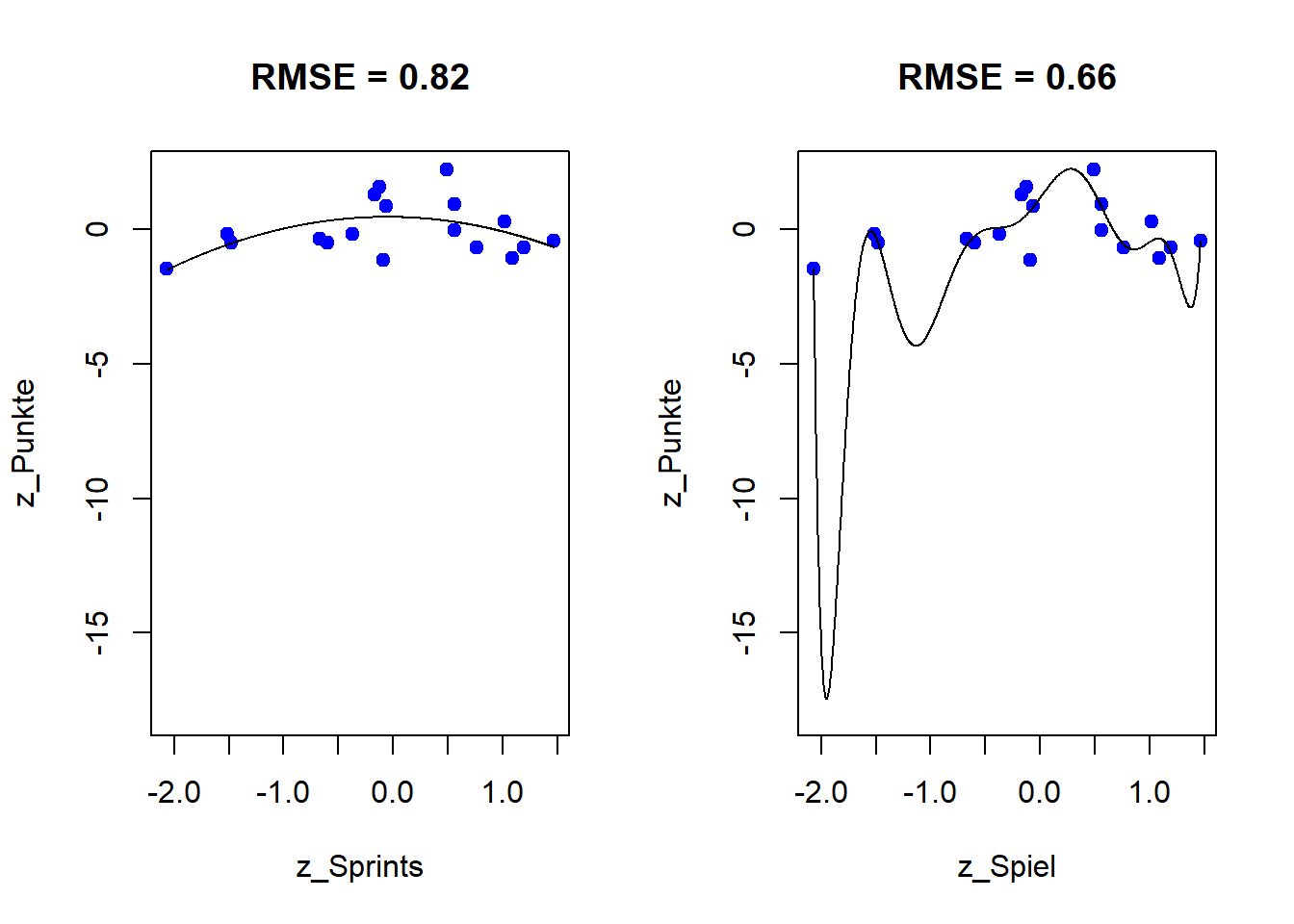
Auf der z-Skala ist der RMSE direkt in Standardabweichungen interpretierbar.
Das Modell Grad 10 passt die Trainingsdaten noch etwas besser, der typische Fehler ist kleiner als beim Modell Grad 2. Bis hierhin wirkt das komplexere Modell überlegen.
Gute Passung ist keine gute Vorhersage
Spannend wird es, wenn wir dieselben Modelle auf neue Daten anwenden.
Wir betrachten nun die Saison 22/23, standardisieren wieder Punkte und Sprints und verwenden die Modelle, die auf den 24er Daten geschätzt wurden, um die 23er Punkte vorherzusagen.
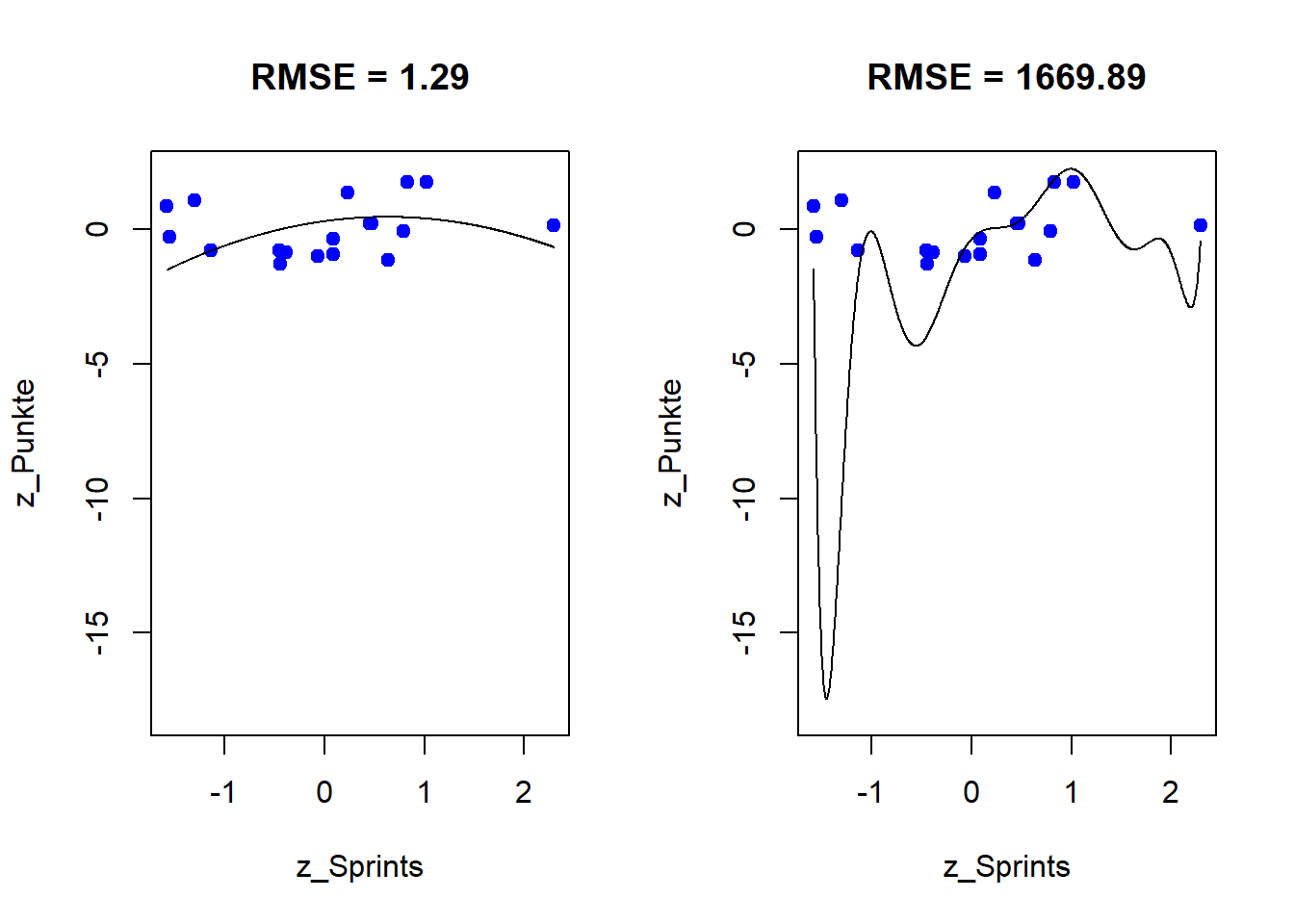
In den Grafiken sieht man die deutlich schlechtere Passung. Zur Bewertung berechnen wir wieder den RMSE, jetzt aber nicht auf den 24er Trainingsdaten, sondern auf den 23er Vorhersagen.
RMSE für die Saison 22/23 mit Modell Grad 2: etwa 1,29
RMSE für die Saison 22/23 mit Modell Grad 10: etwa 1669,89
Die echten z-Punkte liegen ungefähr im Bereich von vielleicht −2 bis +2. (!)
Das Modell 2. Grades liegt im Schnitt etwa 1,29 Standardabweichungen daneben. Das ist bereits schlechter als ein triviales Modell, das immer nur den Mittelwert vorhersagt (RMSE = 1 auf der z-Skala).
Beim Modell 10. Grades “explodieren” die Vorhersagen vollständig: Es sagt für manche Teams Werte im Bereich von über 7000 Standardabweichungen voraus. Die quadratischen Fehler sind daher gigantisch, und der RMSE landet bei etwa 1669. Das Modell ist für Vorhersagen damit faktisch unbrauchbar.
Mathematisch lässt sich das als Overfitting beschreiben: Das Modell 10. Grades nutzt seine vielen Freiheitsgrade, um die 24er Daten sehr präzise zu modellieren. Die Struktur, die es gelernt hat, ist aber so an diese eine Saison angepasst, dass sie auf die Saison 22/23 also andere Daten, nicht übertragbar ist.
Fazit
Das Beispiel zeigt:
Hohe Varianzaufklärung im Trainingsdatensatz (hohes \(R^2\), kleiner RMSE) bedeutet nicht, dass ein Modell gute vorhersagen macht.
Polynome hohen Grades können die Trainingsdaten sehr gut treffen, scheitern aber auf neuen Daten dramatisch.
Ohne theoretische Leitplanken beschreibt Curve-Fitting häufig Zufallsschwankungen statt systematischer Zusammenhänge.
Für die Praxis heißt das:
Polynommodelle können zur Exploration interessant sein, sollten aber nie allein über ihre Passung auf einem Datensatz bewertet werden. Wichtiger sind theoretische Überlegungen und die Frage, wie sich ein Modell auf neue, unabhängige Daten überträgt.
Literatur
Colonescu, C. (2016). Principles of Econometrics with R. https://bookdown.org/ccolonescu/RPoE4/prediction-r-squared-and-modeling.html
Marewski, J. N., & Olsson, H. (2009). Beyond the null ritual: Formal modeling of psychological processes. Zeitschrift für Psychologie/Journal of Psychology, 217(1), 49–60.