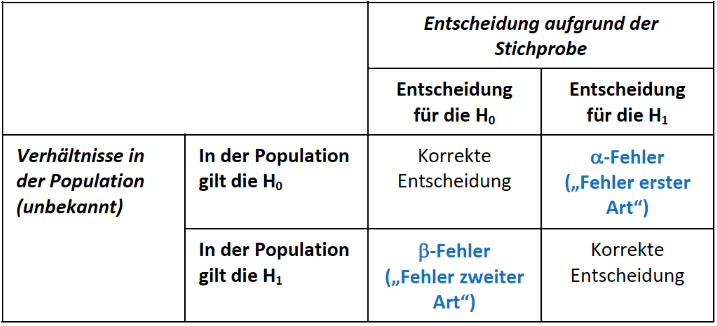
Die Irrtumswahrscheinlichkeit \(\alpha\) bezeichnet die Wahrscheinlichkeit, mit der die H0 abgelehnt wird, obwohl sie gilt. Betrachten wir die Idee des Hypothesentestens nach Neyman und Pearson in einer 4-Felder-Tafel, um den \(\alpha\)-Fehler von anderen Entscheidungsmöglichkeiten abzugrenzen.
Im Folgenden wollen wir nur \(\alpha\) betrachten und gehen daher von der Prämisse aus, dass zufällig normalverteilte Variablen vorliegen, für deren Zusammenhänge stets die \(H_0\) gilt (keine Zusammenhänge / Unterschiede zwischen den Variablen). Außerdem wählen wir für alle Berechnungen eine Wahrscheinlichkeit von \(\alpha = 0.05\)
Beginnen wir mit einer kleinen Simulation des \(\alpha\)-Fehlers bei Mittelwertsvergleichen mit dem \(t\)-Test. Wir erzeugen 10 000 \(t\)-Tests mit den zufälligen Variablen A und B, die den gleichen Mittelwert und die gleiche Standardabweichung bzw. Varianz besitzen (\(\bar{x} = 0\) und \(\sigma_{x}^2 = 1\)):
options(digits =4)set.seed(052023)N <-10p_values <-replicate(n =10000, expr = { d <-data.frame(A =rnorm(N), B =rnorm(N)) p <-t.test(x = d$A, y = d$B, var.equal = T)$p.valuereturn(p) } )# Betrachten wir 25 zufällige p-Werteround(p_values, 2)[sample.int(25)]
In 25 zufällig gewählten p-Werten sehen wir an der 12. Stelle einen \(p\)-Wert \(\leq 0.05\). Das ist der \(\alpha\)-Fehler, denn laut unserer Definition gibt es keine Mittelwertsunterschiede zwischen den Variablen A und B in der Simulation.
Betrachten wir alle 10 000 Simulationen, finden wir 493 \(p\)-Werte \(\leq 0.05\), was einem Anteil von 0.049 entspricht (nahezu unser \(\alpha\) von 0.05).
sum(p_values <= .05); mean(p_values <= .05)
[1] 493
[1] 0.0493
Der kumulierte \(\alpha\)-Fehler
Der kumulierte \(\alpha\)-Fehler gibt die Wahrscheinlichkeit dafür an, dass mindestens ein Test einer Serie von Tests signifikant wird. Eine Serie entspricht also mehrfachen Tests, die wir gedanklich durch eine Matrizenschreibweise erzeugen.
# pc ... pairwise-comparisonspc_2 <-matrix(p_values, nrow =2)pc_2[, 1:10]
Jede Spalte der oben erzeugten Matrix enthält zwei \(p\)-Werte (das könnten die \(p\)-Werte von 2 Vergleichen sein). Nun betrachten wir die Ergebnisse spaltenweise und fragen, wie viele Spalten mindestens einen \(p\)-Wert \(\leq \alpha\) enthalten.
In unserer Ausgabe ist das die 5. Spalte. Hier haben wir also bereits bei einer von 10 Testserien einmal den \(\alpha\)-Fehler begangen.
Betrachten wir alle \(p\)-Werte in einer 2er Serie, finden wir tatsächlich, dass ca. 10 % der Testserien mindestens ein signifikantes Ergebnis liefern.
mean(apply(pc_2, MARGIN =2, FUN =function(x){any(x <= .05)}))
[1] 0.097
Wird die Serie größer (z. B. 4 Tests), steigt der kumulierte \(\alpha\)-Fehler weiter an.
Bei 4 Vergleichen enthalten bereits drei Spalten (3, 7 und 8) mindestens ein signifikantes Ergebnis.
mean(apply(pc_4, MARGIN =2, FUN =function(x){any(x <= .05)}))
[1] 0.1828
Der kumulierte \(\alpha\)-Fehler steigt auf 0.18.
Formale Berechnung
Der kumulierte \(\alpha\)-Fehler (\(\bar {\alpha }\)) lässt sich mit \(m\) (der Anzahl der Tests pro Serie) berechnen (unter der Annahme unabhängiger Tests):
Diese Ergebnisse decken sich mit denen unserer Simulation.
Erweiterungen
Mehrfachvergleiche und einfaktorielle ANOVA
Nun untersuchen wir die Mittelwertsunterschiede von 4 Variablen A, B, C und D (was einer einfaktoriellen ANOVA mit 4 Gruppen entspricht). Dazu benötigen wir 6 Paar-Vergleiche, also 6 einzelne \(t\)-Tests.
Wir erwarten also:
\[\bar{\alpha}=1-(1-0.05)^{6} = 0.26\]
set.seed(052023)N <-10p_values_aov <-replicate(n =1000, expr = { d <-data.frame(A =rnorm(N), B =rnorm(N), C =rnorm(N), D =rnorm(N)) ps <-c(t.test(x = d$A, y = d$B)$p.value,t.test(x = d$A, y = d$C)$p.value,t.test(x = d$A, y = d$D)$p.value,t.test(x = d$B, y = d$C)$p.value,t.test(x = d$B, y = d$D)$p.value,t.test(x = d$C, y = d$D)$p.value )return(ps) } )mean(apply(p_values_aov, MARGIN =2, FUN =function(x){any(x <= .05)}))
[1] 0.214
In unserer Simulation p_values_aov erhalten wir jedoch nur \(\bar{\alpha}=0.21\).
Das ist erklärungsbedürftig!
Werden die Variablen im Paar-Vergleich mehrfach herangezogen (z. B. der Vergleich A–B und A–C), clustern sich die falsch-signifikanten Ergebnisse innerhalb einer Serie. Weicht die Variable A zufällig vom Mittelwert ab, wird bei dem Vergleich mit B bzw. C oder D ein \(\alpha\)-Fehler wahrscheinlicher. Beim Auszählen von mindestens einem signifikanten Ergebnis wird der kumulierte \(\alpha\)-Fehler also geringer. Um das zu verdeutlichen vergleichen wir die Anzahl signifikanter Ergebnisse innerhalb einer Serie nochmal mit der der 1. Simulation:
# Vergleich mindestens 2 signifikante Ergebnisse in einer Serie# Simulation 1pc_6 <-matrix(p_values, nrow =6)sum(apply(pc_6, MARGIN =2, FUN =function(x){sum(x <= .05) >=2}))
Bei unabhängigen Stichproben ist die Wahrscheinlichkeit für mehr als ein signifikantes Ergebnis 0.053, bei Mehrfachvergleichen innerhalb eines Datensatzes steigt die Wahrscheinlichkeit hingegen auf 0.071. Die \(\alpha\)-Fehler bei Vergleichen mit den selben Variablen clustern sich innerhalb einer Testserie.
In dem Beitrag α-Inflation Teil 2 werden wir uns den Mehrfachvergleichen bei mehrfaktoriellen ANOVA-Designs widmen.