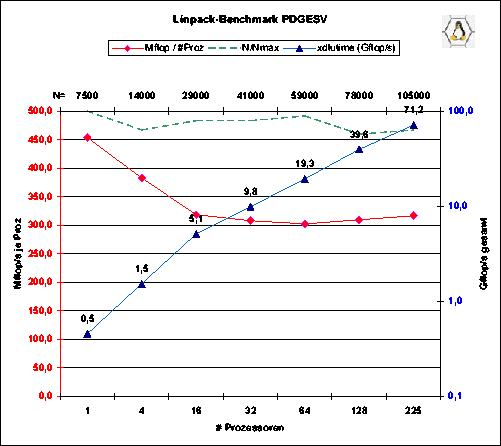
Der Vergleich der erreichten Linpack-Performance auf verschiedener Knotenanzahl des CLIC zeigt, wie gut die Rechenleistung bei Vervierfachung bzw. Verdopplung der Prozessorzahl und entsprechender Vergrößerung der Systemdimension skaliert.
Die Abbildung zeigt die Gesamtleistung des Systems [Gflop/s] und die dabei auf jeden Prozessor entfallende Leistung [Mflop/s]. Der Test verwendet SCALAPACK, MPIBLACS, ATLAS und LAM-MPI.
Die Tests mit dem neuen
HPL-Benchmark
wurden erst nach der offiziellen Einweihung aufgenommen.
Bei den ersten Tests kam ein Subcluster mit 484 Knoten auf 143.3
Gflop/s, was in der zu dieser Zeit aktuellen
Top500-Liste (November 2000) Platz 126 bedeutete.
Die aktuelle Liste von November 2001
weist den CLIC mit der im September erzielten Leistung von 221.6 Gflops auf Platz 137 aus (das alte Ergebnis wäre nur
noch Platz 259 wert).
Im September 2001 wurde der volle Ausbau der Maschine mit dem HPL-Benchmark
getestet. Ergebnis: 221,6 Gflop/s (mehr als 50% der theoretischen Peak-Leistung)
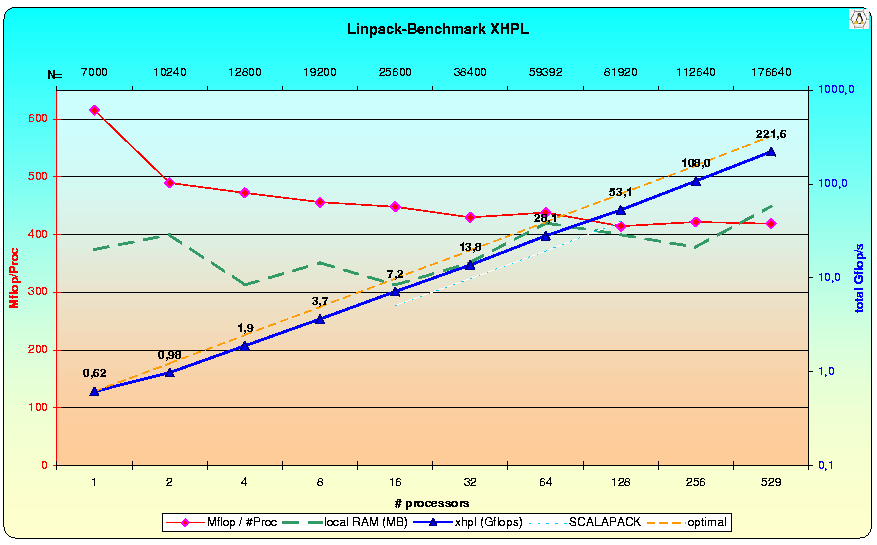
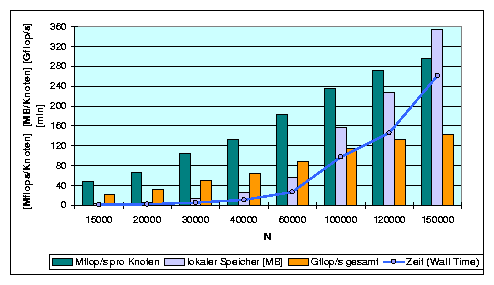
Das Diagramm zeigt u.a. die Gesamtleistung in Abhängigkeit von der benutzten Knotenanzahl, die dabei erreichte mittlere Leistung pro Knoten, die Speicherauslastung der Knoten und eine linear extrapolierte (optimale) Leistung, die denkbar wäre, wenn keine Kommunikation erforderlich wäre.
Bei gleicher Prozessorzahl zeigt die Tabelle, dass die maximale Performance nur mit maximaler Hauptspeicherauslastung zu erzielen ist - ein Grund dafür, dass sich solche Benchmark-Rechnungen sehr lange hinziehen ...
mpirun N -np 225 xdlutime.atlas_PIII.lam Simple Timer for ScaLAPACK routine PDGESV Number of processors used: 225 TIME N NB P Q LU Time Sol Time MFLOP/S Residual CHECK ---- ------ --- --- --- --------- --------- ---------- ---------- ------- WALL 1000 64 15 15 35.67 2.93 17.31 0.001162 PASSED WALL 5000 64 15 15 31.29 0.44 2627.31 0.000722 PASSED WALL 10000 64 15 15 57.30 1.09 11419.54 0.000690 PASSED WALL 15000 64 15 15 118.40 1.54 18763.07 0.000511 PASSED WALL 20000 64 15 15 202.91 1.98 26033.78 0.000377 PASSED WALL 25000 64 15 15 324.54 2.42 31861.90 0.000419 PASSED WALL 30000 64 15 15 501.76 2.85 35673.84 0.000355 PASSED WALL 35000 64 15 15 678.77 3.35 41906.66 0.000349 PASSED WALL 40000 64 15 15 924.97 3.88 45937.71 0.000413 PASSED WALL 50000 64 15 15 1574.51 4.70 52771.38 0.000362 PASSED WALL 100000 64 15 15 10902.71 9.18 61096.80 0.000330 PASSED WALL 100000 40 15 15 9645.20 22.52 68959.49 0.000368 PASSED WALL 105000 40 15 15 10761.86 75.67 71212.37 362.994 PASSED**) Der Knoten, der hier (wegen RAM-Defekt) falsche Werte lieferte, wurde inzwischen ausgewechselt.
<0:0> SCORE: 484 hosts, single process/host ready. ============================================================================ HPLinpack 1.0 -- High-Performance Linpack benchmark -- September 27, 2000 Written by A. Petitet and R. Clint Whaley, Innovative Computing Labs., UTK ============================================================================ An explanation of the input/output parameters follows: T/V : Wall time / encoded variant. N : The order of the coefficient matrix A. NB : The partitioning blocking factor. P : The number of process rows. Q : The number of process columns. Time : Time in seconds to solve the linear system. Gflops : Rate of execution for solving the linear system. The following parameter values will be used: N : 15000 ............. NB : 40 80 [160] P : 22 22 Q : 22 22 PFACT : Right NBMIN : [ 1 -->>>> ] 8 NDIV : 2 RFACT : Right BCAST : 1ringM DEPTH : 1 SWAP : Mix (threshold = 80) [(threshold = 160)] L1 : transposed form U : transposed form EQUIL : yes ALIGN : 8 double precision words ============================================================================ T/V N NB P Q Time Gflops ---------------------------------------------------------------------------- W11R2R1 15000 40 22 22 93.50 2.407e+01 W11R2R8 20000 40 22 22 157.91 3.378e+01 W11R2R8 30000 40 22 22 355.41 5.065e+01 W11R2R8 40000 80 22 22 664.07 6.425e+01 W11R2R8 60000 80 22 22 1625.22 8.861e+01 W11R2R8 100000 40 22 22 5852.66 1.139e+02 W11R2R8 120000 80 22 22 8743.16 1.318e+02 W11R2R8 150000 80 22 22 15699.66 1.433e+02
Das Diagramm zeigt anhand dieser Messreihe die Abhängigkeit der Performance von der Auslastung der Prozessoren.