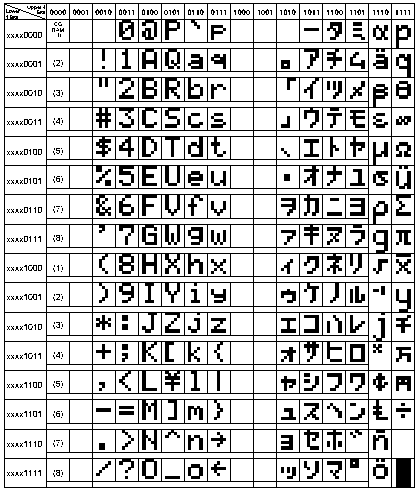
So genannt, weil er so in den meisten Flüssigkristallanzeigen
in dieser Belegung »fest eingebrannt« ist.
Ursprung ist der im verbreiteten Controller-Chip HD44780 eingesetzte
Zeichensatz.
Es gibt zwar auch andere Zeichengenerator-Belegungen;
diese sind mir bis jetzt noch nicht untergekommen.
Im »normalen« ASCII-Bereich 20h..7Eh gibt es immerhin zwei Zeichenpositionen, die nicht standardkonform belegt sind:
"\")
"~")
Für die Kleinbuchstaben g, j, p, q und y empfiehlt sich die Substitution vor der Ausgabe durch hübschere Zeichen mit Unterlänge (mittels OR 80h). Außer, der Kursor steht unter dem Zeichen.
Für den Bereich A0h..DFh (halbbreite Katakana, eine der beiden japanischen Silbenschriftarten, siehe auch Lehrbuch-Einleitung) sind die Standard-Unicodes angegeben; diese Kode-Positionen entsprechen im übrigen exakt dem Unicode-Bereich U+FF60..U+FF9F (=Präsentationsformen).
Hinweis: Präsentationsformen sind nicht für den Datenaustausch gedacht, sondern für die Verarbeitung und (unterschiedliche) Darstellung innerhalb des Computersystems.
Für eine gute Darstellung von deutschem Text empfiehlt es sich, fünf »Sonderzeichen« (Ä, Ö, Ü, ü, ß) als benutzerdefinierte Zeichen im Kode-Bereich ab 08h abzulegen, weil diese Zeichen fehlen bzw. arg missraten sind.
Zur Abdeckung des ASCII-Zeichensatzes brauchen Sie noch\(Rückwärtsstrich) und~(Tilde). Da bleibt nur noch eine von 8 programmierbaren Zeichenpositionen übrig
Intern darf ein Mikrocontroller seine Zeichenketten durchaus in „Hitachi-Kode“ speichern, etwa:
str: db "M",0EFh,"beltrans",'p'+80h,"ort",0 // "Möbeltransport"Beim Datenaustausch bspw. über die serielle Schnittstelle sollte eine Transkodierung zu UTF-8 vorgenommen werden.
Kode-Beispiele später...
Tabelle als Bild entnommen aus »hd44780.pdf«, dem Datenblatt des gleichnamigen
Schaltkreises.